

Ubuntu自定义软路由
前言
为什么会有这篇文章呢?其实是因为我很早之前就对“以Linux为底层的软路由系统”很感兴趣,之前在学校学的就是网络工程和系统服务部署,因此对Linux系统和网络可以说还是比较熟悉的(特别是网络,有Datacom HCIE认证)。最开始搜软路由就会出现很多的OpenWRT,iKuai,RouterOS这样的文章,不过我只玩了段时间的OpenWRT + iStoreOS。
iStoreOS虽然在某些设计上确实很方便(比如web界面配置等),但使用一段时间下来还是感觉不顺心,这玩意儿怎么这么臃肿复杂,把一些很简单的事情做的很复杂,后来想了想,可能因为OpenWRT刚开始就是为了web界面的路由器设计的,要对新手友好些,但对外来说很多功能其实没必要了,而且OpenWRT的很多功能我都可以自己手搓实现。并且,会尽可能的将每一个服务都进行最大限度的性能优化,确保软路由的运行速度和效率,对我来说这是必须的~
基于以上原因,最终选择简洁的Ubuntu Server 25.04,且安装时选择最小安装来实现,为了保证在物理机上可一次性完美安装和功能实现,所有要部署的服务都会先在虚拟机上进行实验,确认没问题后才会上物理机,确保物理机系统的干净整洁(在这方面还是有洁癖的)。
另外提一嘴,2025年09月05日晚22:00,在小黄鱼上购买了一台多网口小主机(N5105)做软路由,虽然之前买过天钡家的AMD款的天钡 WTR PRO安装飞牛用到现在,但是一直没有做过软路由,因此耗“巨资”购买了它。
甚是喜欢呢,哈哈,不过夏天被动散热效率太低了,一会就发烫了,后面会整个静音风扇(类似电脑机箱里那个)就够压住了,它主要是没风带走热量,有风的话5分钟温度就降到室温了。

配置过程
以下过程均先在虚拟机上测试后才会“搬运”到物理机上,以下是虚拟机的配置列表,正好对应N5105的配置进行实验。
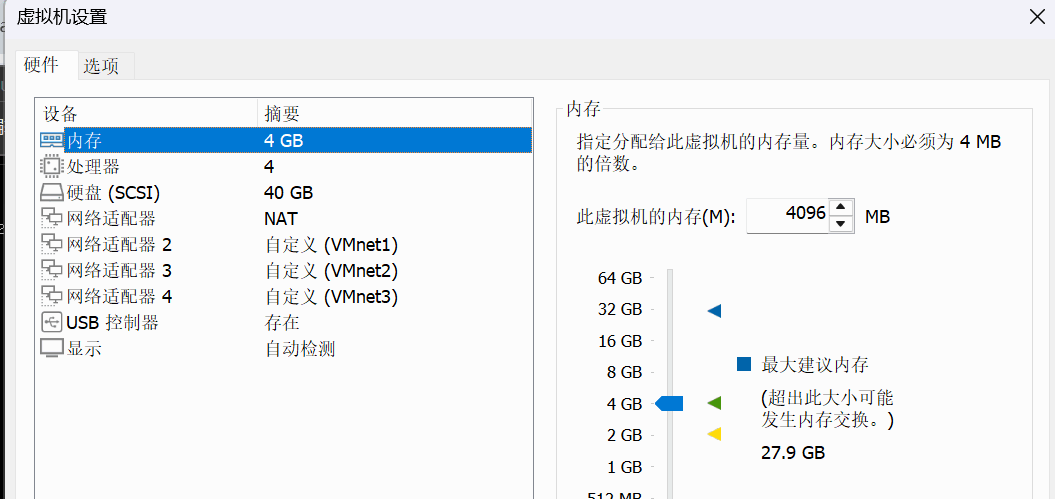
1、系统安装
关于U盘刻录系统镜像,插入机器并通过U盘启动这一步略过,不了解的可以上网查一下,教程太多了。
开机进入系统安装界面
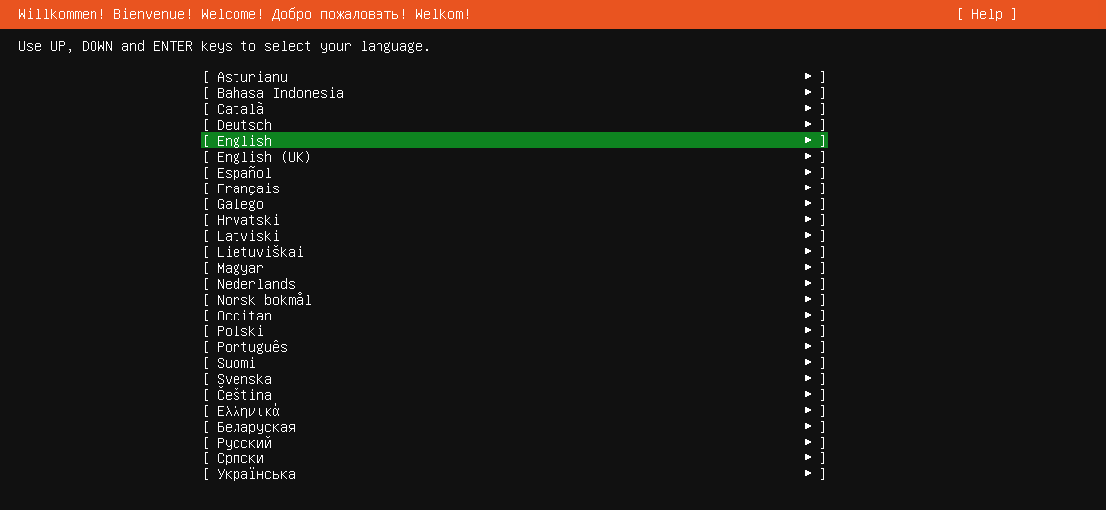
选择English,随后进入到更新安装包的阶段,如果选择第一个update to the new installer那么需要确保你的机器目前已经连上网了,否则就选择第二个
随后选择键盘格式为English (US)
选择Ubuntu Server (minimized)最小化安装Ubuntu Server,然后就可以看到网卡界面了,目前连接公网的接口已经通过DHCP获取到了地址,可正常上网,其余三个接口后续要做桥接,因此先不配置。
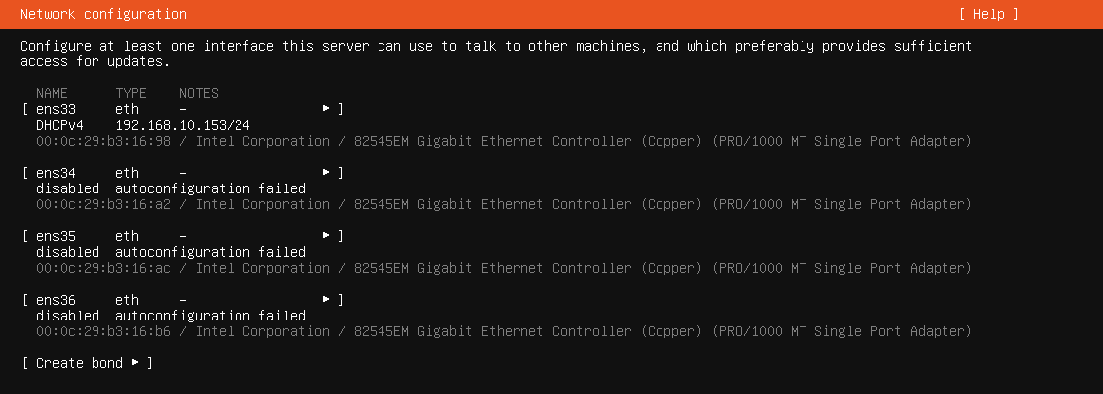
跳过代理,来到软件包更新界面,如果没有要更新的,直接选择Done就行
在存储配置这一界面,为了后期分区扩容什么的方便,选择LVM安装,无需进行LVM加密
随后分区直接Done即可,因为目前设备就一块磁盘,且对于软路由来说不会存储有太多东西,因此直接一整块磁盘都做为根分区即可。
设置账户密码,随后选择安装OpenSSH Server方便后续远程连接。
到达软件包安装界面,虽然后面会用到docker,但目前系统还无法上外网,安装docker可能不顺利,因此都不选择,直接下一步。随后系统就会开始安装,因为选择的是最小安装,因此等待时间不会太久。
远程连接
安装完成重启开机后,因刚才选择了安装OpenSSH Server,因此可直接在windows的cmd中使用下面的命令远程连接到设备上(前提是和外网接口同网络)
ssh 用户名@接口地址
随后要做的就是提权更改root密码,切换root用户,更改ssh配置,使得root用户可使用密钥登录
sudo passwd root # 输入一次ubuntu密码,两次要设置的root密码
su root
vim /etc/ssh/sshd_config
# 修改以下内容
Port 22
SyslogFacility AUTH
LogLevel VERBOSE
PermitRootLogin without-password
LoginGraceTime 2m
DenyUsers xxx # 禁止xxx用户登录
MaxAuthTries 3 # 最大认证次数3
MaxSessions 2 # 最大会话数2
PasswordAuthentication no # 禁止密码验证登录
PermitEmptyPasswords no # 禁止空密码验证
UseDNS no # 不对客户端进行DNS泛解析验证,加快SSH连接速度
PubkeyAuthentication yes # 开启SSH公钥认证登录
AuthorizedKeysFile .ssh/authorized_keys # 用户登录公钥路径,如果该用户需要多设备免密登录,可以再authorized_keys文件内另起一行写入其他设备的公钥,也可以在此配置后再跟上.ssh/xxx_keys即可
RSAAuthentication yes # 允许RSA算法验证在windows终端上生成ssh-key
ssh-keygen -t rsa -b 4096 # 一直回车即可会在C:\users\用户名\.ssh目录下生成一个私钥文件和公钥文件(pub结尾),使用文本文档打开pub文件,复制全部内容到Ubuntu的/root/.ssh/authorized_keys文件内,重启ssh后即可,尝试使用ssh登录可看到无需输入密码就可以进入系统
systemctl restart ssh
systemctl enable ssh
2、安装常用工具并调整系统时区
apt update && apt install iputils-ping traceroute unzip wget curl dnsutils iproute2 net-tools -y调整系统时区
timedatectl set-timezone Asia/Shanghai3、命令行补全
安装bash-completion
apt install bash-completion -y在/etc/bash.bashrc文件下添加脚本命令
if ! shopt -oq posix; then
if [ -f /usr/share/bash-completion/bash_completion ]; then
. /usr/share/bash-completion/bash_completion
elif [ -f /etc/bash_completion ]; then
. /etc/bash_completion
fi
fi退出当前用户终端重新进入即可
4、开启内核的路由转发功能
net.ipv4.ip_forward = 1
net.ipv6.conf.all.forwarding = 1
net.ipv4.tcp_congestion_control = bbr5、安装NetworkManager管理网络
apt install network-manager -y目前Ubuntu Server默认管理网络的工具是netplan,其实是不太方便的,配置network-manager管理网络
vim /etc/NetworkManager/NetworkManager.conf
# 修改下面内容
[ifupdown]
managed=truevim /etc/netplan/00-installer-config.yaml # 每个系统的文件名都不一样,我这里叫00-installer-config.yaml
# 在下添加,注意开头与 version:2 对齐:
renderer: NetworkManager应用netplay并重启NetworkManager(可能会断网,做好准备)
netplay apply
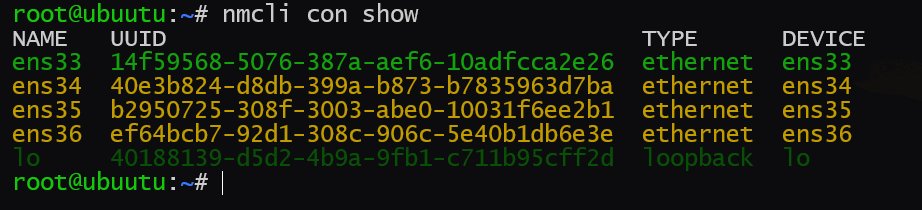
systemctl restart NetworkManager随后查看nmcli接管情况
nmcli con show出现下面类似的输出说明接管完成

修改各网卡的Connect Name为网卡名称,为方便可选择使用Network Manager的伪图形化界面快速修改
nmtui效果如下
6、创建桥接网卡
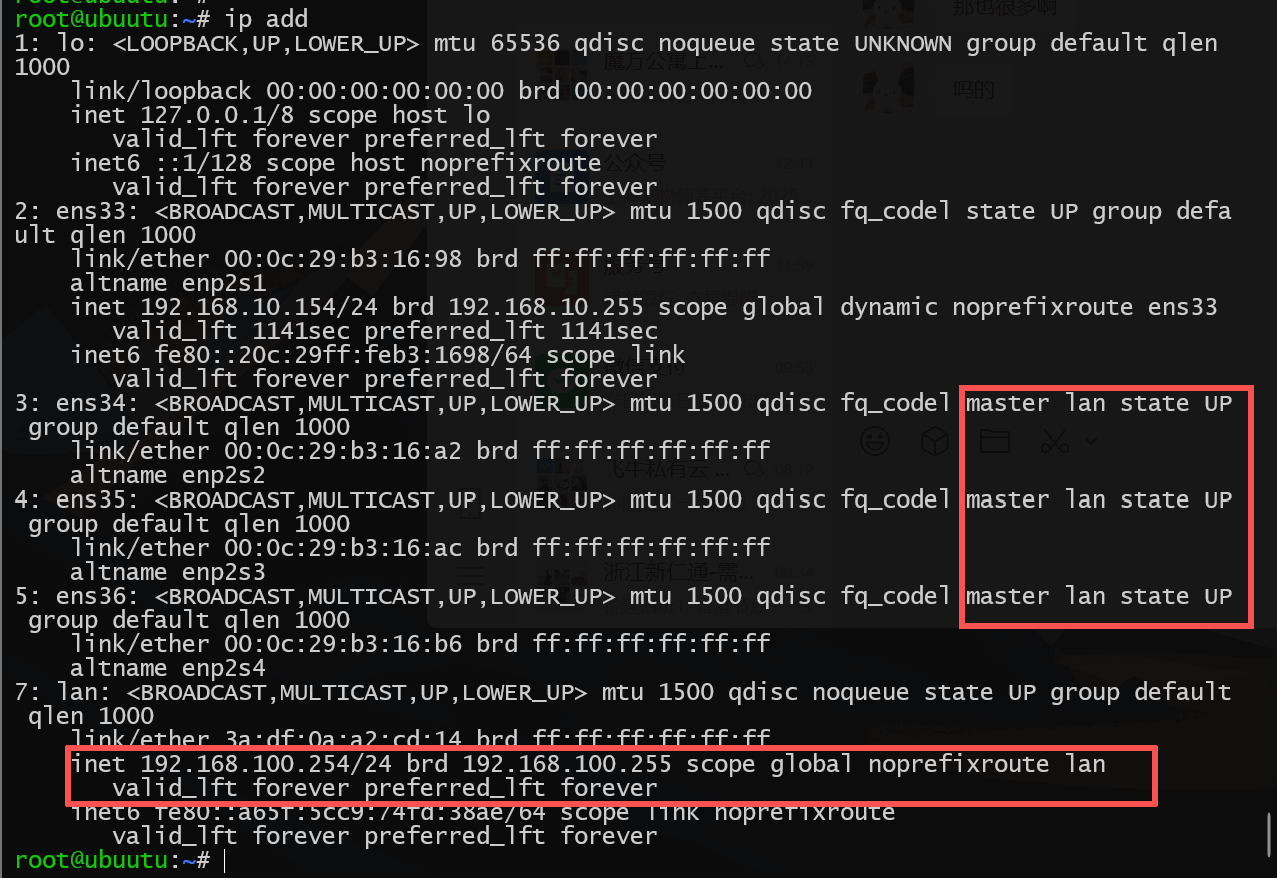
现代光猫、软路由的LAN网卡其实本质上就是一个虚拟的桥接网卡,类似与Switch(交换机),通过将物理网卡绑定在桥接网卡下实现交换机二层网络接口的功能(默认网卡是三层网络,每个接口必须属于一个独立的IP段)
创建虚拟网卡LAN
nmcli con add \
con-name lan \
type bridge \
ifname lan \
ipv4.method manual \
ipv4.addr 192.168.100.254/24 \
ipv6.method auto \
stp no这里我们关闭了STP,因为当LAN接口下没有任何物理端口up时,LAN接口处于关闭状态,接入端口后STP需要经过2个Forwarding时间(30秒)才能进入UP状态,即便进入UP状态,还需要DHCP服务反应一段时间,这就会造成终端在开机或者睡眠结束后无法立马获取到地址上网,需要等待1-2分钟,这是比较痛苦的。
注意:这里如果是在虚拟机中,确保添加的三个内网网卡不属于同一个vmnet,否则,STP不开启的情况下,你将尝到广播风暴的味道~但同时,现实中我们关闭了STP也要确保软路由下接的只有三层接口(终端、路由器等),如果两个接口接同一个交换机,一定要开STP或者聚合接口,要不然也是会环路的
将三张局域网网卡绑定到桥接网卡lan下
nmcli con modify ens34 master lan
nmcli con modify ens35 master lan
nmcli con modify ens36 master lan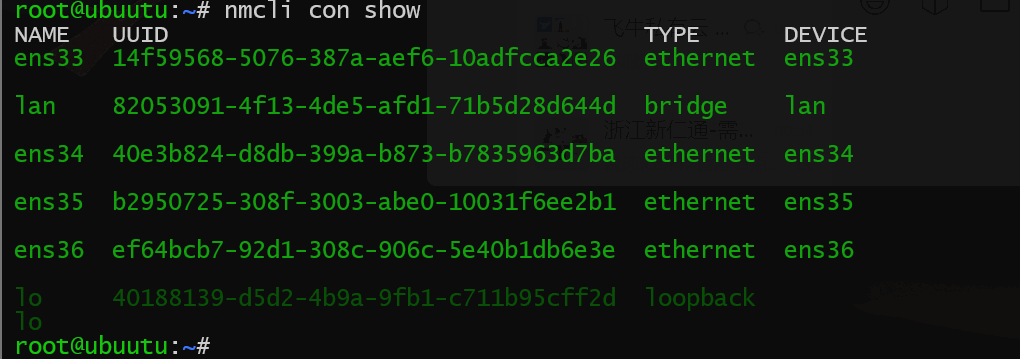
7、配置轻量DHCP服务器
这里有两种轻量选择,一种是dns和dhcp都具备的dnsmasq,另一种是转为dhcp准备的udhcp。后面因为要做流量分流,国内流量和国外流量分开走,需要路由分流和DNS分流,因此需要后面肯定要安装对应的dns服务,但是这里不选择dnsmasq,是因为它在处理大量域名列表的时候太过臃肿,CPU压力大,源于它的设计问题。后面再说,先说DHCP。
这里选择udhcpd是因为他非常的轻量,开发时就是为了嵌入式设备的小型化设备设计的,因此在运行时几乎不消耗资源。
安装udhcpd
apt install udhcpd -y默认udhcpd有一个udhcpd.service只能监听一个网卡下发地址,可以另创建多实例udhcpd的systemctl服务,实现多接口udhcpd也可以实现下发地址
vim /usr/lib/systemd/system/udhcpd@.service
# 加入以下内容
[Unit]
Description=udhcpd DHCP server for interface %i
After=NetworkManager-wait-online.service
Wants=NetworkManager-wait-online.service
[Service]
Type=simple
ExecStart=/usr/sbin/udhcpd -f /etc/udhcpd/udhcpd@%i.conf
Restart=always
PIDFile=/run/udhcpd@%i.pid
[Install]
WantedBy=multi-user.target重新加载配置
systemctl daemon-reload配置UDHCPD服务器
mkdir /etc/udhcpd
vim /etc/udhcpd/udhcpd@lan.conf配置UDHCP服务器
# 指定要下发的地址范围
start 192.168.10.100
end 192.168.10.200
# 请确保这里是要监听DHCP请求的网络接口,例如 eth0, wlan0 等
interface lan
# DHCP租约文件,所有租约都将存储在这里。
lease_file /var/lib/misc/udhcpd@lan.leases
max_leases 101
# 指定到期时间
opt lease 864000 # 10 days of seconds
# 指定要下发的掩码和网关
opt subnet 255.255.255.0
opt router 192.168.10.254
# 指定下发的DNS,如果后面要做DNS分流,一定也要指定dns是本设备
opt dns 192.168.10.254
# 指定光播地址
opt broadcast 192.168.10.255
# 指定下发的域
opt domain home
# 也可以指定静态下发地址
#static_lease 00:60:08:11:CE:4E 192.168.1.55
#static_lease AA:BB:CC:DD:EE:FF 192.168.1.75systemctl restart udhcpd
systemctl enable udhcpd创建租约文件
touch /var/lib/misc/udhcpd@lan.leases启动服务
systemctl restart udhcpd@lan
systemctl enable udhcpd@lan如果后续要创建新的接口udhcpd服务,在/etc/udhcpd目录下创建udhcpd@xx.conf文件后,使systemctl restart udhcpd@xxxsystemctl enable udhcpd@xx即可
8、配置smartdns服务
之前说了dnsmasq在处理大量域名列表的时候太过臃肿,CPU压力大。因此选用smartdns服务,smartdns在设计时就保证了即使处理万级的域名列表也很轻松,特别是我们后面要配置的域名列表内有11万的国内域名列表。11万行的列表,dnsmasq处理时会有很长时间的CPU沾满的情况,绝对不适合,而smartdns即使处理11万行域名列表也可以较为轻松应对。
为什么要进行dns分流?因为国内大厂的站点都有CDN和DNS分流解析,国内DNS服务器和国外DNS服务器解析出来的IP地址不一样,国外的DNS走他们的海外节点,国内的DNS走国内的节点。因此,要进行分流的话,必须要做DNS分流。
SmartDNS官网:
安装smartdns
apt install smartdns -y获取国内域名列表
cd /etc/smartdns
wget -O cn.conf https://raw.githubusercontent.com/felixonmars/dnsmasq-china-list/refs/heads/master/accelerated-domains.china.conf可以先复制到windows电脑内用记事本打开,Ctrl + h 进行替换,把文件内的server=/换成空 ,/114.114.114.114换成空 ,确保每一行只有一个域名
将*.cn加入到列表的最上方,这样如果访问的是.cn域名的站点服务器直接从文件最上方就能匹配到,不需要往下寻找,消耗CPU资源了
*.cn配置smartdns
vim /etc/smartdns/smartdns.conf# 在lan接口监听dns查询
bind :53@lan
# 创建china组且不放入default组,在default组内的server在为明确指定域名对应的dns服务器时,会使用default组内的dns服务器
server 114.114.114.114 -group china -exclude-default-group
server 223.5.5.5 -group china -exclude-default-group
server 223.6.6.6 -group china -exclude-default-group
# 创建global组,并在default组内,当没有明确的域名对应的dns服务器时,会使用default组内的dns服务进行查询,且使用DOH配置
server 8.8.8.8 -group global
server 8.8.4.4 -group global
server 1.1.1.1 -group global
# 创建一个名为cnlist的domain-set,可将cn.conf内容导入到domain-set内快速查询
# -a no -speed-check-mode none确保在使用china组的时候不预先进行测速选择最优服务器,cn.conf文件内容过大的话,测速会导致速度验证下降
domain-set -name cnlist -file /etc/smartdns/cn.conf
nameserver /domain-set:cnlist/china -a no -speed-check-mode none
# IPv6域名解析直接返回为空,在分流中不仅会导致流量无法分流,还会降低smartdns查询速度
force-AAAA-SOA yes
# 指定域名解析缓存大小,缓存到内存中,后续有相同的查询的话就不需要在文件内查询了
cache-size 65536
# 禁用缓存持久化。20万规则下,保存和加载缓存文件会成为启动和关闭时的性能瓶颈,且可能产生冲突。
cache-persist no
prefetch-domain yes
# 最小TTL值
rr-ttl 300
# 允许的最小TTL值
rr-ttl-min 300
# 允许的最大TTL值
rr-ttl-max 86400
# 只记录致命错误
log-level fatal
# 每个上游返回的IP数量,减少处理开销
max-reply-ip-num 4
# 关闭双栈测速,节省资源
dualstack-ip-selection no这里解释一下:
smartdns在针对某个域名指定查询DNS服务器的时候可以使用conf-file和domain-set两种方法,这里使用domain-set。domain-set 的方案在处理每个DNS查询时,CPU消耗极低且恒定,可将域名列表文件中的每一个域名作为独立的键(Key) 加载到一个高度优化的哈希表中进行哈希查找。收到查询后,SmartDNS 直接计算查询域名的哈希值,然后在哈希表中进行一次查找,立刻知道是否存在。而conf-file是线速查找,顺序遍历。收到一个DNS查询后,SmartDNS 需要从第一条规则开始,依次向下匹配,直到找到匹配项或遍历完所有20万条规则。
使用domain-set,99% 的查询都不会因为匹配这20万条规则而增加任何可感知的延迟。而使用 conf-file,每个查询都可能因为要遍历巨大的规则列表而产生几毫秒甚至更高的延迟,这在网络游戏中是致命的。并且domain-set能处理的每秒查询量(QPS) 会远高于conf-file方案,在高负载环境下更加稳定。
总而言之,在cn.conf文件内容在万级时,使用smartdns绝对是性能优化的最优解!
使得resovectl不监听系统网卡53端口,但是还是处理上游dns服务器,防止和dnsmasq冲突
vim /etc/systemd/resolved.conf
DNSStubListener=nosystemctl restart systemd-resolved.service由于smartdns 是在NetworkManager前启动的,而dnsmasq中的lan接口又是NetworkManager创建的,因此会导致dnsmasq在系统启动时无法得知lan接口导致启动失败,将其调整为NetworkManager后启动
vim /usr/lib/systemd/system/smartdns.service
# 修改以下内容
After=NetworkManager-wait-online.service
Wants=NetworkManager-wait-online.service重新加载配置
systemctl daemon-reload可选配置
DOH,加密global组内的DNS查询,防止DNS查询信息泄漏
# 创建global组,并在default组内,当没有明确的域名对应的dns服务器时,会使用default组内的dns服务进行查询
#server 8.8.8.8 -group global
#server 8.8.4.4 -group global
#server 1.1.1.1 -group global
# 注释掉原本的global组配置
server-https https://8.8.8.8/dns-query -group global
server-https https://dns.google.com/dns-query -group global
server-https https://1.1.1.1/dns-query -group global
server-https https:/cloudflare-dns.com/dns-query -group global
server-tcp 8.8.8.8
server-tcp 1.1.1.1
server-https https://dns.google/dns-query -group global
server-https https://doh.opendns.com/dns-query -group global9、使用OpenVPN进行科学上网和流量分流
篇幅太长,看我之前的文章
这里要注意,安装openvpn-dco的话,有小部分概率tun网卡使用会不顺畅,具体看文章开头,目前只在inter cpu遇到过,而且我配置了十几台服务器了,只见过这一次。
另外注意一下:
1、设置好DNS和路由分流后,苹果设备如果在iCloud中开启了专用代理那么流量就会通过苹果的服务器再做一层VPN代理加密,不仅会导致苹果设备分流失败,还会导致数据转发效率低(因为加密和隧道做了两次),如果希望进行分流,建议关闭专用代理后重启设备。
2、即便是关掉专用代理,有可能发现访问抖音APP还是会走隧道,但是访问其他APP就不会(比如CSDN),那么这种情况就是抖音有了海外CDN的缓存或者打了标记,删除重装一下就好了。
10、调整系统启动时间
ubuntu18以后使用netplan管理网络,会有一个毛病,就是如果NetworkManager作为netplan的后端服务的话,默认的systemd遗留下来的systemd-networkd-wait-online这个服务无法正常监听到网络启动,导致系统启动时间有2分钟超时时间等待服务超时。既然我们已经用了NetworkManager,那就直接给它禁用吧,已经没用了,而且NetworkManager也有自己的wait-online服务(NetworkManager-wait-online.service)
systemctl disable systemd-networkd-wait-online.service重启系统即可发现开机速度快了
11、配置防火墙和NAT
以下是nftables防火墙的加速数据包转发、NAT和有状态包过滤防护配置,内容太大了,不单独解释,没学过的自行查资料
netfilter官网:
vim /etc/nftables.conf#!/usr/sbin/nft -f
flush ruleset
# 预定义配置
define lan_int={ lan, wlp6s0 }
define wan_int={ enp1s0 }
define vpn_ip={ 10.10.10.0/24, 10.10.20.0/24, 10.10.30.0/24 }
table inet filter {
# flowtables,数据包卸载功能,匹配的数据包可绕过prerouting、routing、forwarding和postrouting hook直接跳出netfilter,减少cpu消耗
flowtable myft {
hook ingress priority filter;
devices = { enp1s0, lan, wlp6s0 }
counter
}
chain input {
type filter hook input priority filter; policy drop;
# 放行已建立连接和与连接相关的连接(有状态防火墙)
ct state { established, related } accept
iif "lo" accept
iif $lan_int accept
ip saddr $vpn_ip accept
iif $wan_int ip protocol tcp tcp dport { 22 } accept
}
chain forward {
type filter hook forward priority filter; policy drop;
# 将已建立连接和与连接相关的连接调用在加速数据转发的flowtable中(要放在accept之前,否则直接放行了,不会被匹配)
ct state { established, related } flow add @myft
# 放行已建立连接和与连接相关的连接(有状态防火墙)
ct state { established, related } accept
iif $lan_int accept
ip saddr $vpn_ip accept
}
chain output {
type filter hook output priority filter; policy accept;
ct state { established, related } accept
}
chain postrouting {
type nat hook postrouting priority 100; policy accept;
# 出接口非环回接口和LAN接口时进行SNAT伪装
oif !={ lo, lan } masquerade
ct state { established, related } accept
}
}加载nftables规则并设置为开机自启动
nft -f /etc/nftables.conf
systemctl enable nftables同样的还是修改nftabels的启动顺序在NetworkManager之后
vim /usr/lib/systemd/system/nftables.service
# 修改以下内容,并
After=NetworkManager-wait-online.service
Wants=NetworkManager-wait-online.servicesystemctl daemon-reload12、安装docker
国内安装docker会受限制,因此使用阿里云软件源进行安装
# 从阿里云镜像源下载 Docker 官方 GPG 密钥(国内访问快,无 SSL 连接问题)
# 并转换为 apt 可识别的密钥格式,保存到系统密钥目录
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg# 生成适配当前系统架构和版本的阿里云 Docker 源配置
# 其中:
# - $(dpkg --print-architecture) 自动获取系统架构(如 amd64)
# - $(lsb_release -cs) 自动获取 Ubuntu 系统版本代号(如 jammy、focal)
# - signed-by 指定已添加的阿里云密钥路径,确保源验证通过
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null# 更新软件包索引(此时会从阿里云源获取信息,速度快且稳定)
sudo apt update
# 安装 Docker 引擎及相关组件(docker-ce 为 Docker 引擎,docker-ce-cli 为命令行工具,containerd.io 为容器运行时)
sudo apt install docker-ce docker-ce-cli containerd.io
# 配置docker开机自启动
sudo systemctl enable docker检验docker是否安装
docker info
-----------------------------------------------------------------------
Client: Docker Engine - Community
Version: 28.4.0
Context: default
Debug Mode: false
Plugins:
buildx: Docker Buildx (Docker Inc.)
Version: v0.27.0
Path: /usr/libexec/docker/cli-plugins/docker-buildx
compose: Docker Compose (Docker Inc.)
Version: v2.39.2
Path: /usr/libexec/docker/cli-plugins/docker-compose
.......................关闭docker自动生成防火墙配置,后面我们自己配置,并且设置docker默认桥接网卡的ip地址
vim /etc/docker/daemon.json{
"iptables": false,
"ip6tables": false,
"bip": "192.168.17.1/24"
}重启docker生效
systemctl restart docker13、配置IPv6相关内容
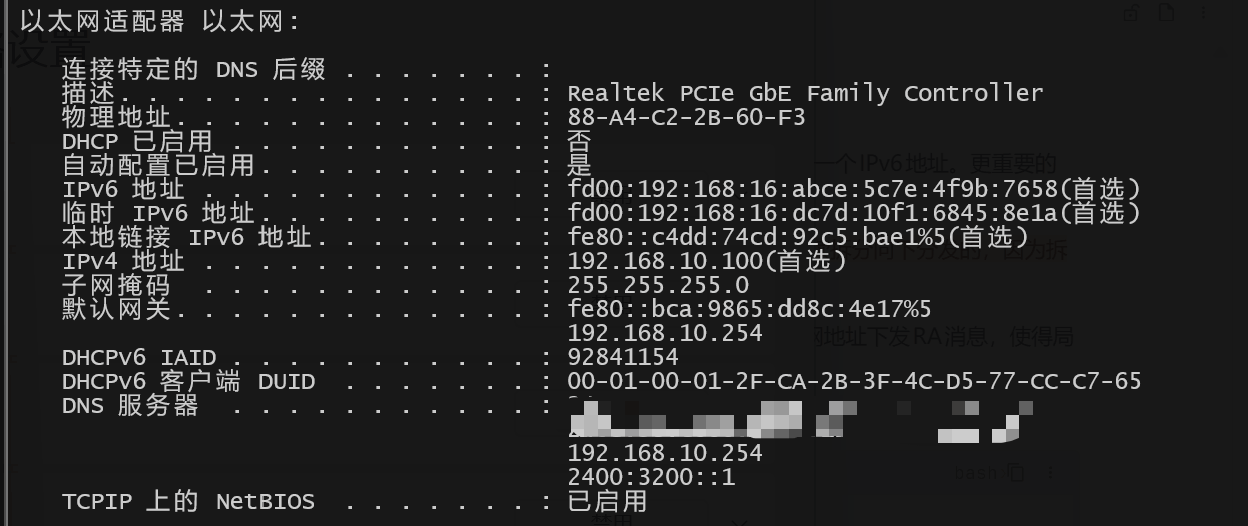
在有IPv6地址的环境下,我们为了方便访问内网设备,肯定是要获取IPv6地址的,外网接口从运营商获取到ICMPv6的RA报文,从中提取IPv6前缀并根据eui64生成一个IPv6地址。更重要的是,我们还要通过这个获取到的前缀为局域网内的设备下发IPv6地址。
以上前提:光猫是桥接模式,由ubuntu路由器复制PPPOE拨号,得到运营商下发的PD前缀才可,大多为56或50。否则最多获取到/64的地址,/64的地址是不能继续拆分向下分发的,因为拆分的话就到/65了,而下发ipv6地址最少要求的是/64;
如果ubuntu路由器只能通过RS/RA获取到/64的地址,那么,LAN接口下的设备是无缘公网IPv6地址了,只能WAN接口获取/64地址,然后LAN接口配置/64的私网地址下发RA消息,使得局域网获取到一个私网的/64前缀生成地址。如果希望WAN侧主机通过IPv6访问内网主机,需要做DNAT才可以。
配置外网接口获取IPv6地址
nmcli con modify ens33 ipv6.method auto \
ipv6.addr-gen-mode eui64 \
ipv6.ip6-privacy 0nmcli con up ens33 # 重启外网接口然后使用ip addr查看接口是否获取到IPv6地址随后进行LAN接口配置
nmcli con modify lan ipv6.method shared \
ipv6.address fd00:192:168:100::1/64nmcli con up lan # 重启内网接口随后LAN接口下的终端主机在开启IPv6功能后即可通过ICMPv6的RS和RA报文获取对应的IPV6地址和IPv6 DNS信息

14、配置无线网络
🤔 关于无线网络调优要点:
如果你的无线网卡接口是Mini PCIE的,建议不要选择Intel的,Intel的很多Mini PCIE无线网卡作为热点(AP模式) 来发射Wi-Fi信号时,对其大部分消费级网卡的驱动进行了软件锁定,而且AP模式发射的2.4G信号特别差。这是Intel 为MiniPCIE接口网卡设计时就决定了主要作为Client模式使用而非AP模式。使用其他品牌的无线网卡或者USB网卡可以得到很好的解决。
通常来说WiFi信号强度和用户体验,是发射功率(单位:dBm)和天线(包括增益和覆盖模式,单位:DB)共同作用的结果。因此即使发射功率较小,但天线数量和信号覆盖范围大也有很流畅的使用体验。但最好还是功率和天线增益都高一些的好。
另外,当你使用5G信号时,在不考虑无线网卡自身性能(如支持的技术标准)的前提下,信道数和信道宽度(Channel Width)是决定Wi-Fi数据吞吐量(即速度)最关键的因素之一。
上面说了Mini PCIE无线网卡接口的软路由尽量不要选择Intel无线网卡,可能踩坑,我这里使用的是联发科的MT7922网卡。在使用时,这款网卡在Linux系统能较好地支持AP模式,有较高的传输速率,6.8以上的内核无需手打驱动。再者,我后面购买了一代的无线网卡延长线和天线(增益3DB),无线信号覆盖范围已经可以将我的出租屋全方位覆盖,如果你家里很大需要更大的信号覆盖范围,建议购买8/12DB的增益天线或者外接AP组网。
软路由无线组网方式有三种,根据自己的要求进行选择
🤔 软路由无线组网的三种方法:
1、使用主板内置插槽;
大部分小主机内置了有PCIE或Mini PCIE插槽的无线网卡,可以选择一个合适的无线网卡+增益天线进行释放无线信号;2、使用USB无线网卡;
与使用主板插槽类似,但是USB无线网卡通用性强,也省心,通常USB无线网卡的功率都比较高,自带增益天线。3、外接AP;
使用软路由作为核心路由,下联接口插入一个家用路由器(最好支持仅AP模式),这种组网是信号覆盖范围和速率最好的。
在配置无线网络时,有三种NetworkManager方法可以进行配置(传统可能使用hostapd服务,但是过于麻烦,而NetworkManager提供了快速简便的方法进行配置)
🤔 释放无线信号的三种方法:
1、使用”个人热点“;
2、手动配置各种参数;
3、桥接到LAN网卡(推荐);
以上三种方法的区别在于:
个人热点:创建后NetworkManager会使用内置的dnsmasq下发dhcp和dns,方便快捷,但是无线网卡和LAN网卡属于不同的三层网络,需要配置不同的IP段,且如果手动配置了DHCP和DNS服务,会无法下发地址,因为接口对应端口已经被监听;
手动配置DHCP和DNS参数:这种方式下所有参数都需要手动配置,包括DHCP和DNS,但是无线网卡和LAN网卡属于不同的三层网络,需要配置不同的IP段。且需要独立配置第二个DHCP实例监听无线网卡的DHCP请求;
桥接到LAN网卡:此模式下,LAN网卡和无线网卡共用一个三层IP和IPv6,对于无线网卡来说,它不需要管IP下发的问题,只需要发射无线信号、设置密码,随后把客户端的对应数据上送给LAN网卡,由LAN网卡统一下发DHCP、DNS等。这也是家用路由器常见的做法,无线客户端获取到的IP地址是和有线客户端一个网段的。
下面举例三种模式的创建方法(5G Channel 36),如果无法启动且报错 Error: Connection activation failed: 802.1X supplicant took too long to authenticate,可能存在多种原因,如:配置了当前国家代码下不允许使用的配置、无线接口模式为shared但已经被别的服务监听了53和67,68端口、网卡不支持5G或高MHz等等;
首先将自己的无线网卡国家代码设置为CN,避免因为默认处于严格限制的00而使得很多功能禁止使用(80MHz信道宽度和某些提升无线安全和性能的功能)
iw reg set CN以上命令为临时修改,使用下面的方法写入内核模块参数,创建或编辑下面的文件
vim /etc/modprobe.d/cfg80211.conf
# 添加以下内容
options cfg80211 ieee80211_regdom="CN"更新initramfs确保在引导时加载,随后重启系统无线国家代码也是CN了
update-initramfs -u查看附近wifi所处的大部分信道
nmcli device wifi list查看网卡支持的信道,[ ]外没有写disabled和no IR的都是可以使用的
iw list | grep -A 10 "dBm"根据如何配置一个没有使用或最少使用的信道,信道与信道之间最少相隔5,我这里没人使用信道149
个人热点配置(shared模式确保会自动下发地址)
nmcli device wifi hotspot \
con-name SoftRouting \
mode ap \
ifname wlx0013ef6f25bd \
ssid SoftRouting \
802-11-wireless-security.key-mgmt wpa-psk \
802-11-wireless-security.psk xxxx \
802-11-wireless.band a 802-11-wireless.channel 36 \
ipv4.method shared \
ipv4.address 192.168.20.254/24nmcli con up SoftRouting手动配置:
nmcli con add con-name SoftRouting \
ifname wlx0013ef6f25bd \
type wifi \
mode ap \
802-11-wireless.ssid SoftRouting \
802-11-wireless-security.key-mgmt wpa-psk \
802-11-wireless-security.psk xxxx \
802-11-wireless.band a 802-11-wireless.channel 36 \
ipv4.method manual \
ipv4.address 192.168.20.254/24 nmcli con up SoftRouting桥接到LAN网卡配置
nmcli connection add con-name SoftRouting \
ifname wlx0013ef6f25bd \
type wifi \
master lan \
wifi.mode ap \
wifi.ssid SoftRouting \
wifi-sec.key-mgmt wpa-psk \
wifi-sec.psk Ljr1873599@ \
802-11-wireless.band a \
802-11-wireless.channel 149 nmcli con up SoftRouting
nmcli con up lan扩展:设置加密方式为更安全的WPA2(AES),默认是TKIP和AES混用,而客户端连接时可能选择到了不安全的TKIP
nmcli con modify SoftRouting \
802-11-wireless-security.proto rsn \
802-11-wireless-security.pairwise ccmp \
802-11-wireless-security.group ccmp nmcli con up SoftRouting
nmcli con up lan开启AP隔离(可选),无线终端之间无法互访
nmcli con modify SoftRouting 802-11-wireless.ap-isolation true禁用省电模式,确保无线网卡始终处于高性能状态
nmcli con modify SoftRouting 802-11-wireless.powersave disable查看无线信息
iw dev wlx0013ef6f25bd info
-------------------------------------------------------------------------------------------------------
Interface wlx0013ef6f25bd
ifindex 6
wdev 0x1
addr 00:13:ef:6f:25:bd
ssid SoftRouting
type AP
wiphy 0
channel 149 (5745 MHz), width: 20 MHz, center1: 5745 MHz
txpower 19.00 dBm
multicast TXQ:
qsz-byt qsz-pkt flows drops marks overlmt hashcol tx-bytes tx-packets
0 0 6308 0 0 0 0 995117 8377传输功率的单位是 dBm。数值越大,信号覆盖范围越广。常见家用路由器的功率一般在 20 dBm(100mW)左右。
这里有个踩坑点,如果你使用的无线网卡是MT792x的,且系统是6.8的内核,那么你大概率会看到只有3dbm的功率,这在2025年的2月已经修复了,是内核补丁修复人员说这是误报,实际功率正常。如果你不想更换内核,且测速正常的话就不用管了(MT7921/2正常无线桥接下的5G模式80MHz信道宽度的情况下带宽应该在700Mbps左右)。
查看客户端连接信息(需要已有连接的客户端)
iw dev wlp6s0 station dump
-------------------------------------------------------------------------------------------------------
Station 5e:7c:0b:29:d6:56 (on wlp6s0)
inactive time: 29757 ms
rx bytes: 3435638710
rx packets: 2569586
tx bytes: 3683176612
tx packets: 2643850
tx retries: 115217
tx failed: 63
rx drop misc: 0
signal: -29 [-34, -30] dBm
signal avg: -29 [-33, -30] dBm
tx bitrate: 780.0 MBit/s VHT-MCS 9 80MHz VHT-NSS 2
tx duration: 140452409 us
rx bitrate: 866.7 MBit/s VHT-MCS 9 80MHz short GI VHT-NSS 2
rx duration: 40286512 us
last ack signal:-28 dBm
avg ack signal: -28 dBm
airtime weight: 256
authorized: yes
authenticated: yes
associated: yes
preamble: long
WMM/WME: yes
MFP: yes
TDLS peer: no
DTIM period: 2
beacon interval:100
short slot time:yes
connected time: 3361 seconds
associated at [boottime]: 8987.760s
associated at: 1758546903718 ms
current time: 1758550264908 ms其中的tx bitrate:173.3 MBit/s和rx bitrate:173.3 MBit/s分别是网卡的最大上传和下载速度
更改网卡信道宽度(需要网卡支持),以获得更大的带宽吞吐量。(标准的80MHz所使用的信道为36, 40, 44, 48 而160MHz则因每一组都可能会有雷达干扰,因此除非在偏远地区,否则很多情况下甚至表现不如80MHz,使用的话推荐信道36, 40, 44, 48, 52, 56, 60, 64)
nmcli con modify SoftRouting 802-11-wireless.channel 36
nmcli con modify SoftRouting 802-11-wireless.channel-width 80mhz
nmcli con up SoftRouting 再次查看无线网卡信息
phy#0
Interface wlx0013ef6f25bd
ifindex 6
wdev 0x1
addr 00:13:ef:6f:25:bd
ssid SoftRouting
type AP
channel 48 (5240 MHz), width: 80 MHz, center1: 5210 MHz
txpower 18.00 dBm
multicast TXQ:
qsz-byt qsz-pkt flows drops marks overlmt hashcol tx-bytes tx-packets
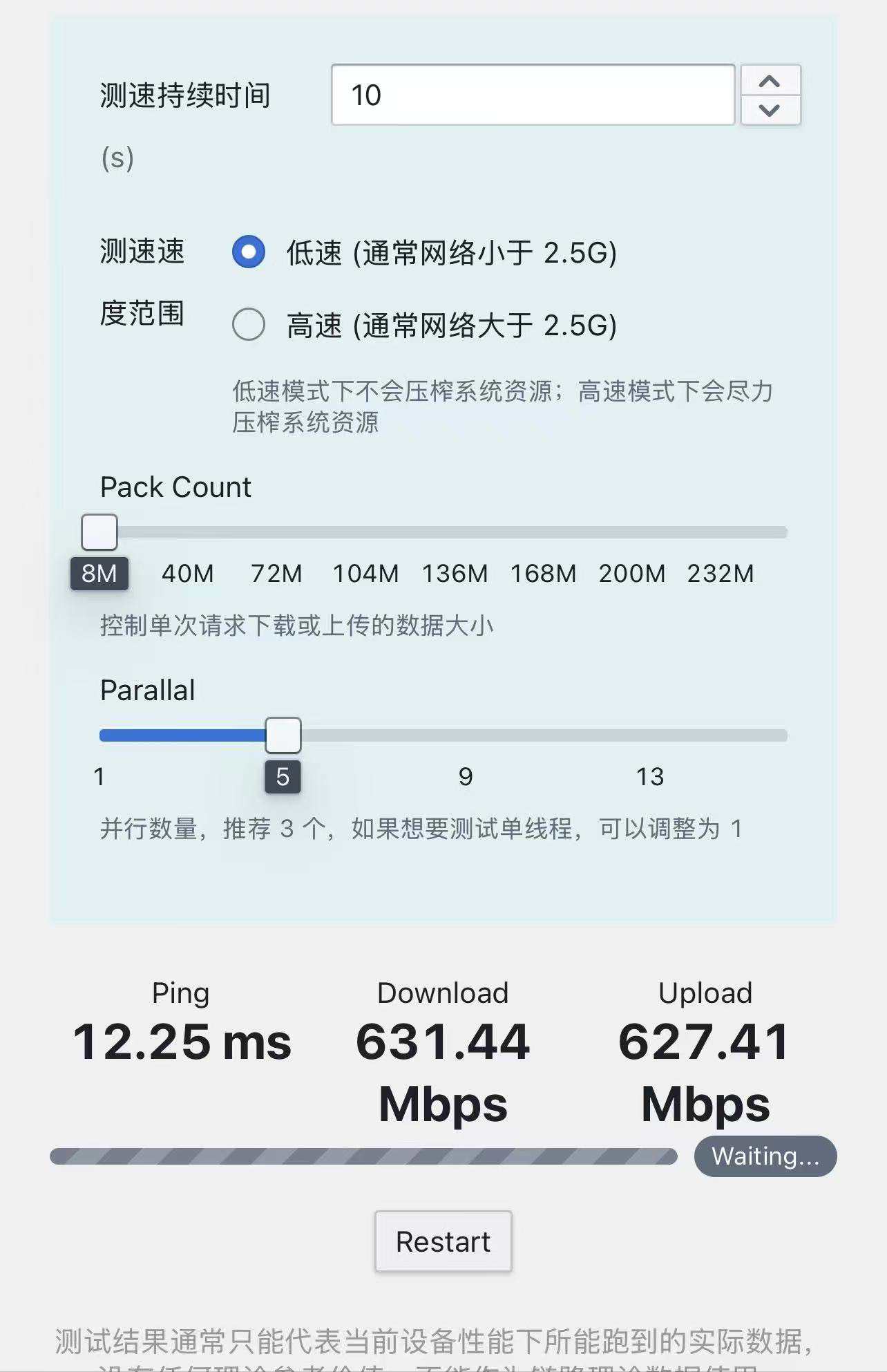
0 0 277 0 0 0 0 38459 332测速后发现上下行均可达650mbps左右(homebox测速)
15、部署DDNS-GO
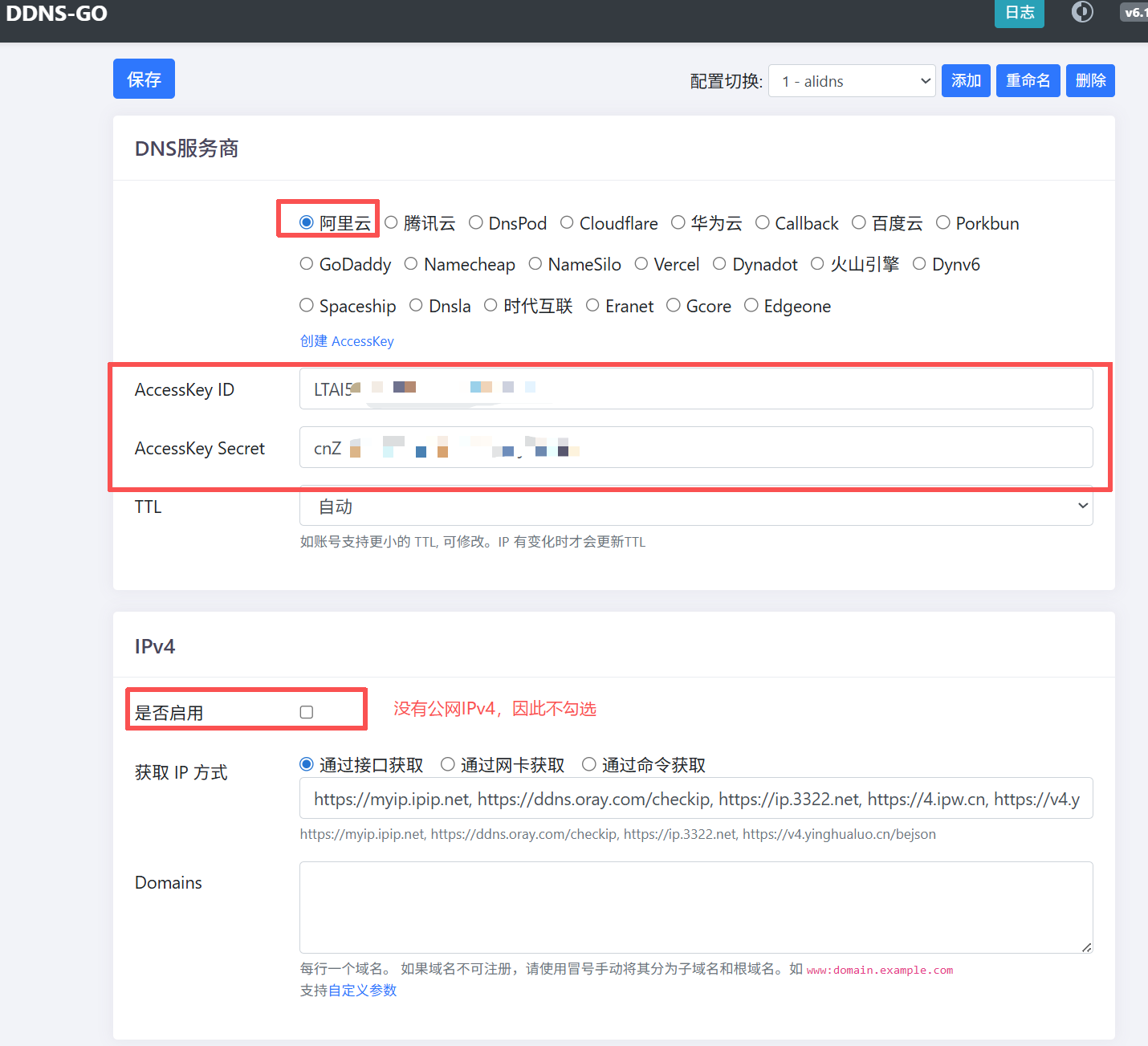
上面我们通过RS和RA报文让WAN侧接口获得了运营商下发的公网IPv6地址,但这个地址是会随机变化的,如果希望可以远程管理不太方便。因此我们需要部署DDNS-GO,将域名与IPv6地址绑定,同时定时检测IPv6地址是否发生变化,检测到变化后自动将域名提供商内DNS的解析地址改变。前提是有域名,我已经提前买了一个域名并且完成了备案。
首先确保接口获得的IPv6地址是单个的,不存在“临时地址”
nmcli con modify ens33 ipv6.method auto \
ipv6.addr-gen-mode eui64 \
ipv6.ip6-privacy 0nmcli con up ens33docker部署
docker pull jeessy/ddns-gomkdir /Docker_Data/ddns-go
docker run -d --name ddns-go --restart=always --network=host -v /Docker_Data/ddns-go:/root jeessy/ddns-go随后LAN侧获取到地址后浏览器输入网关地址+9876即可进入配置界面
随后为了方便远程管理,打开WAN侧的IPv6 SSH端口,这里要注意:为了安全,一定要使用密钥登录并关闭密码登录,最好后面再配置Fail2ban防止SSH爆破。修改后的input规则如下
chain input {
type filter hook input priority filter; policy drop;
ct state { established, related } accept
iif "lo" accept
iif $lan_int accept
ip saddr $vpn_ip accept
iif $wan_int ip6 nexthdr icmpv6 accept
iif $wan_int ip6 nexthdr tcp tcp dport { 22 } accept
iif $wan_int ip protocol tcp tcp dport { 22 } accept
}nft -f /etc/nftables.conf尝试使用IPv6地址SSH登录,前提:SSH客户端已经可通过IPv6正常上网;
16、流量记录
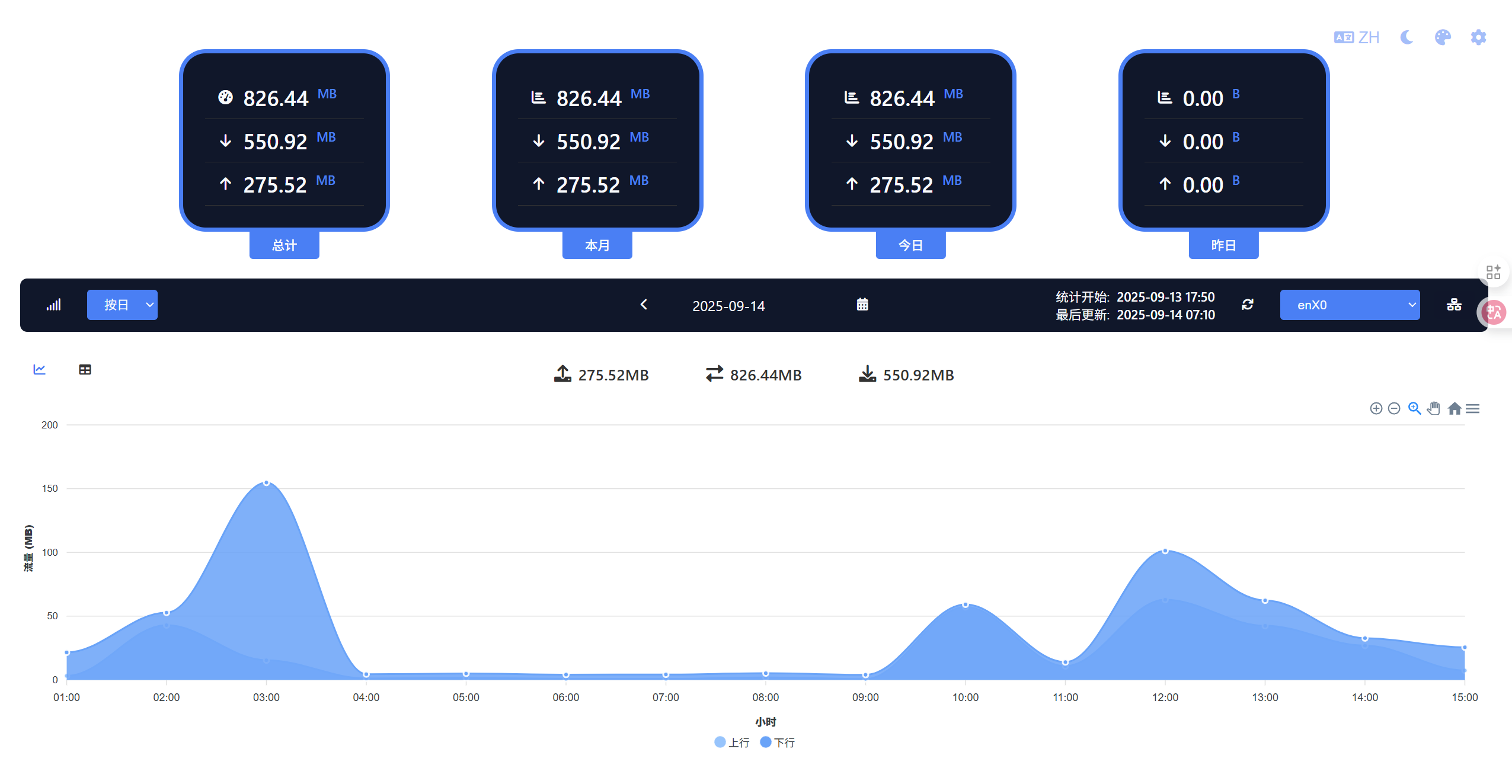
在网上有很多专业级的开源监控系统,但是对于我们的路由器来说,过于丰富的功能是一个累赘,但我们又需要一个界面美观的流量监控。于是经过我一天的查找和部署,找到一个国内作者开发的基于docker版vnstat的网卡监控web界面,有着资源占用极小,界面美观大气的优点,下面是部署过程
制作镜像(可选)
如果你必须制作,可以使用作者已经做好的镜像me1dlinger/vnstat_dashboard
git clone https://github.com/me1dlinger/vnstat_dashboard.git
cd /vnstat_dashboard/vnstat_assist这里发现作者设置的镜像源不对,而且我的设备可以直接上外网,因此删除其中dockerfile中镜像源的配置后执行下面的命令
docker build -t opennw/vnstat-dashboard .构建完成后,先使用下面的命令部署docker版的vnstat
docker run -d \
--restart=always \
--network=host \
-e HTTP_PORT=9695 \
-v /etc/localtime:/etc/localtime:ro \
-v /etc/timezone:/etc/timezone:ro \
--name vnstat \
vergoh/vnstat随后部署刚才构建好的镜像
mkdir -p /Docker_Data/vnstat/log/python
mkdir -p /Docker_Data/vnstat/backups
docker run -d \
--name vnstat-dashboard \
--network=host \
--restart=always \
-v /Docker_Data/vnstat/log/python:/app/log/python \
-v /Docker_Data/vnstat/backups:/app/backups \
-e VNA_AUTH_ENABLE=1 \
-e VNSTAT_API_URL=http://127.0.0.1:9695/json.cgi \
-e VNA_SECRET_KEY=public \
-e VNA_EXPIRE_SECONDS=3600 \
-e VNA_USERNAME=admin \
-e VNA_PASSWORD=admin \
opennw/vnstat-dashboard如果不想进行认证,将VNA_AUTH_ENABLE=设置为1,VNA_USERNAME、VNA_PASSWORD和VNA_SECRET_KEY可以不设置,但需要你确保足够安全,只有你可以访问。(但是web界面还是需要填用户名密码,只是随便写就行)
成功运行后,浏览器输入 http://xxxx:19328进入登录界面,此时需要先点击右上角 设置图标,填入你的web界面地址和默认网卡名。注意是web界面地址,不是vnstat的json.cgi地址。
保存后输入账户名密码即可进入流量监控界面,但注意,只有vnstat-docker运行时,才能有正常的流量记录,且首次部署需要等待5分钟才能看到采集的流量记录
17、拦截广告
smartdns可以拦截广告域名并把解析地址指向0.0.0.0,从而达到拦截广告的目的。可以手动捕捉广告域名,也可以在这个项目里提取:
cd /etc/smartdns/
touch blacklist.txt将广告域名添加进blacklist.txt中
将下面的内容加入到smartdns.conf文件中,记得放在cnlist的前面,确保在匹配到分流域名前先匹配到黑名单列表
# 广告域名domain-set,将解析结果指向0来阻止广告,使用domain-set加快查询
domain-set -name blacklist -file /etc/smartdns/blacklist.txt
address /domain-set:blacklist/0 -a no -speed-check-mode none重启smartdns,随后,在blacklist列表中的广告域名就会被拦截。主要表现为:
1、部分页面广告消失;
2、无法拦截站点作者嵌入页面的图片链接或弹窗样式;
还有一种Adgurad项目拦截广告的,更为高级,但是对我来说用处不大,需要的可以在Github搜索这个项目
18、查看SSH登录成功和失败信息
在Ubuntu24.04及之前,我习惯使用last和lastb输出ssh登录成功和失败信息,用于查看是否有人尝试爆破,但不知为何,在Ubuntu24.10开始不在提供last和lastb命令。last还可以安装wtmpdb实现,但是lastb已经无法安装了,也没有替代命令。可以选择读取auth.log文件内容或写一个脚本,但注意,如果脚本是实时监控的,在遇到SSH爆破时每秒百次的爆破就可能耗尽CPU资源,因此还是建议筛选auth.log文件内容。
为了方便使用,我们可以在环境变量中设置别名,将以下内容加入到/etc/bash.bashrc文件内
alias last='echo ""; echo "------------------登录成功信息------------------"; cat /var/log/auth.log | grep -a Accepted | grep -a from | awk '\''{ gsub(/T/, " ", $1); sub(/\..*/, "", $1); print $1, $4, $7, $9 };'\''; echo ""'
alias lastb='echo ""; echo "------------------登录失败信息------------------"; cat /var/log/auth.log | grep -a Failed | grep -a from | awk '\''{ gsub(/T/, " ", $1); sub(/\..*/, "", $1); print $1, $4, $7, $9 }'\''; echo ""; echo "-----------------无效用户登录信息-----------------"; cat /var/log/auth.log | grep -a Invalid | grep -a from | awk '\''{ gsub(/T/, " ", $1); sub(/\..*/, "", $1); print $1, $4, $6, $8 }'\''; echo ""'退出当前用户后再次登录,即可使用last命令和lastb命令
19、使用Fail2ban进行防护
篇幅过长不再讲述,可以看我原文,里面详细介绍了Fail2ban防止SSH爆破、Nginx CC攻击等行为的处理
20、数据转发调优
禁用无线网卡省电模式,确保无线网卡始终处于高性能状态
nmcli con modify SoftRouting 802-11-wireless.powersave disable增大网卡收发数据时的缓冲区大小,防止流量大时丢包
nmcli con modify eth0 ethtool.ring-rx 8192 ethtool.ring-tx 8192
nmcli con modify eth1 ethtool.ring-rx 8192 ethtool.ring-tx 8192
nmcli con modify eth2 ethtool.ring-rx 8192 ethtool.ring-tx 8192
nmcli con modify eth3 ethtool.ring-rx 8192 ethtool.ring-tx 8192
nmcli con modify SoftRouting ethtool.ring-rx 8192 ethtool.ring-tx 8192启用卸载(GRO/GSO/TSO等,与 nftables flowtable 互补)
nmcli connection modify eth0 ethtool.feature-gro on ethtool.feature-gso on ethtool.feature-tso on ethtool.feature-rx on ethtool.feature-tx on ethtool.feature-sg on ethtool.feature-rxhash on ethtool.feature-ntuple on ethtool.channels-combined 4 ethtool.coalesce-rx-usecs 0
nmcli connection modify eth1 ethtool.feature-gro on ethtool.feature-gso on ethtool.feature-tso on ethtool.feature-rx on ethtool.feature-tx on ethtool.feature-sg on ethtool.feature-rxhash on ethtool.feature-ntuple on ethtool.channels-combined 4 ethtool.coalesce-rx-usecs 0
nmcli connection modify eth2 ethtool.feature-gro on ethtool.feature-gso on ethtool.feature-tso on ethtool.feature-rx on ethtool.feature-tx on ethtool.feature-sg on ethtool.feature-rxhash on ethtool.feature-ntuple on ethtool.channels-combined 4 ethtool.coalesce-rx-usecs 0
nmcli connection modify eth3 ethtool.feature-gro on ethtool.feature-gso on ethtool.feature-tso on ethtool.feature-rx on ethtool.feature-tx on ethtool.feature-sg on ethtool.feature-rxhash on ethtool.feature-ntuple on ethtool.channels-combined 4 ethtool.coalesce-rx-usecs 0
nmcli con modify SoftRouting ethtool.feature-gro on ethtool.feature-gso on ethtool.feature-tso on ethtool.feature-rx on ethtool.feature-tx on ethtool.feature-sg on ethtool.feature-rxhash on ethtool.feature-ntuple on ethtool.channels-combined 4 ethtool.coalesce-rx-usecs 0解释
ethtool.feature-gro on全称:Generic Receive Offload (GRO,通用接收卸载)。
作用:在网卡接收侧,将多个小数据包(segments)聚合为更大的包,减少内核处理中断次数和 CPU 开销。适用于高流量接收场景,提升 PPS(每秒包数)约 10-20%。
适用:下载/转发大流量时推荐启用。ethtool.feature-gso on全称:Generic Segmentation Offload (GSO,通用分段卸载)。
作用:在发送侧,允许内核将大包(> MTU)保持完整发送到网卡,由网卡硬件分段成小包,减少 CPU 分段计算。GSO 是 TSO 的通用版,支持 UDP 等协议。
适用:高带宽上传时,降低 CPU 负载。ethtool.feature-tso on全称:TCP Segmentation Offload (TSO,TCP 分段卸载)。
作用:GSO 的 TCP 特定实现,由网卡计算 TCP 校验和并分段大 TCP 包。比软件分段快,尤其在 10G+ 链路。
适用:TCP 为主的流量(如 web、文件传输);与 GSO 结合使用。ethtool.feature-rx on全称:Receive Checksum Offload (RX 校验和卸载)。
作用:将接收包的校验和(checksum)验证从 CPU 移到网卡硬件,加速包处理。减少错误包重传。
适用:所有接收流量;默认多为 on,但显式启用确保一致。ethtool.feature-tx on全称:Transmit Checksum Offload (TX 校验和卸载)。
作用:发送包时,由网卡计算并填充校验和,卸载 CPU 计算负担。
适用:高吞吐发送场景,与 RX 配对使用。ethtool.feature-sg on全称:Scatter-Gather I/O (散射-聚集 I/O)。
作用:允许网卡使用非连续(scatter-gather)内存缓冲区传输数据,提高 DMA(直接内存访问)效率,减少内存拷贝。
适用:大数据包或多缓冲传输时,提升整体 I/O 性能。ethtool.feature-rxhash on全称:Receive Hashing (接收哈希)。
作用:基于包头(IP/TCP/UDP 元组)计算哈希,将接收流量均匀分发到多个 RX 队列(RSS),实现多核负载均衡。
适用:多队列网卡 + 多核 CPU 时,防止单队列瓶颈。ethtool.feature-ntuple on全称:n-Tuple Filtering (n 元组过滤)。
作用:扩展 RX 哈希,支持基于更细粒度流规则(n-tuple,如源/目标端口)将包引导到特定队列,进一步优化流量分类和负载均衡。需与 rxhash 结合。
适用:复杂流量(如虚拟化、NFV)场景,提高精确分发。ethtool.channels-combined 4: 作用:设置网卡的 combined channels(组合通道/队列)数量为 4。这里的 "combined" 表示 RX(接收)和 TX(发送)队列共享这些通道,而不是分开设置(separate RX/TX)。它启用 RSS(Receive Side Scaling) 和 multi-queue 支持,将传入/传出数据包分布到多个 CPU 核心处理。通常设置为cpu核心数。
适用:负载均衡,减少锁争用(lock contention),适合多流 forwarding(如 nftables offload)。结合 RPS/RFS,效果更好ethtool.coalesce-rx-usecs 0:
作用:设置 RX coalescing(接收中断合并)的 usecs(微秒)延迟为 0。这意味着网卡在收到数据包后 立即(0 us 延迟)触发 CPU 中断,而不是等待一段时间积累多个包再中断(默认 ~50-100 us)。
适用:在高负载 forwarding 下,减少包缓冲时间,PPS +10-20%。适合实时路由,低延迟,但会增大CPU负载。
重启网卡生效,注意以上调优不适合虚拟网卡LAN,但是物理网卡调整后LAN也会生效
nmcli con up SoftRouting
nmcli con up eth0
nmcli con up eth1
nmcli con up eth2
nmcli con up eth3
nmcli con up lan监控
watch -n1 'ethtool -S eth1 | grep -E "rx|tx" && mpstat -P ALL 1 1'apt install sysstat -y
sar -n DEV 1开启nftables flowtables,加速数据转发,降低cpu使用率
table inet filter {
# flowtables,数据包卸载功能,匹配的数据包可绕过prerouting、routing、forwarding和postrouting hook直接跳出netfilter,减少cpu消耗
flowtable myft {
hook ingress priority filter;
devices = { enp1s0, lan, wlp6s0 }
counter
}
chain forward {
type filter hook forward priority filter; policy drop;
# 将已建立连接和与连接相关的连接调用在加速数据转发的flowtable中(要放在accept之前,否则直接放行了,不会被匹配)
ct state { established, related } flow add @myft
# 放行已建立连接和与连接相关的连接(有状态防火墙)
ct state { established, related } accept
iif $lan_int accept
ip saddr $vpn_ip accept
}nft -f /etc/nftables.conf安装irqbalance绑定中断到核心 CPU,避免轮询冲突
apt install irqbalance -y
systemctl enable irqbalance查看irqbalance日志

如果出现上面字样,则使用下面的命令
mkdir -p /etc/systemd/system/irqbalance.service.d
tee /etc/systemd/system/irqbalance.service.d/override.conf > /dev/null <<EOF
[Service]
ProtectKernelTunables=no
EOFsystemctl daemon-reload
systemctl restart irqbalance重新启动进程后等待几分钟查看日志,如果出现下面的字样

应该为这些IRQ被设备的其他驱动所接管,例如NVME等,通常情况下“放任不管”是最好的选择,否则可能影响稳定
安装 cpufrequtils并调整为高性能模式
固定CPU高频转发,减少数据转发时的上下文中断
apt install cpufrequtils -y配置 /etc/default/cpufrequtils或者/etc/init.d/cpufrequtils中的GOVERNOR="ondemand"为GOVERNOR="performance“
重启cpufrequtils
systemctl restart cpufrequtils
systemctl enable cpufrequtils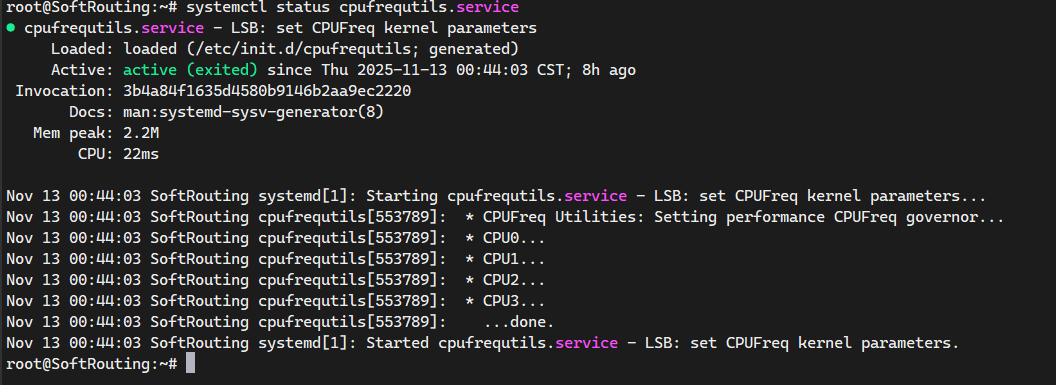
出现上面字样表示设置成功
调整内核参数
ubuntu是一个通用服务器,默认的一些内核参数是为了最为服务器使用的,既然我们要做路由器肯定就需要进行一些内核配置调整
将下面的内容覆盖掉/etc/sysctl.conf文件
# 反向路径验证,防止 IP 欺骗和 DDoS 攻击(0 为关闭,适合 VPN 服务器以避免兼容问题;若无 VPN,建议改为 1)
net.ipv4.conf.default.rp_filter=0
net.ipv4.conf.all.rp_filter=0
# 启用 IPv4 和 IPv6 包转发(路由器核心功能)
net.ipv4.ip_forward=1
net.ipv6.conf.all.forwarding=1
# ECMP哈希优化
net.ipv4.fib_multipath_hash_policy=1
# 禁用 ICMP 重定向,防止 MITM 攻击
net.ipv4.conf.all.accept_redirects=0
net.ipv6.conf.all.accept_redirects=0
net.ipv4.conf.default.accept_redirects=0
net.ipv6.conf.default.accept_redirects=0
# 禁用发送 ICMP 重定向,进一步增强路由安全
net.ipv4.conf.all.send_redirects=0
net.ipv4.conf.default.send_redirects=0
# 禁用源路由包接受,防止 IP 欺骗
net.ipv4.conf.all.accept_source_route=0
net.ipv4.conf.default.accept_source_route=0
# 忽略广播 ICMP Echo 请求,防放大攻击
net.ipv4.icmp_echo_ignore_broadcasts=1
# 启用 IPv4 恶意 ICMP 错误消息保护
net.ipv4.icmp_ignore_bogus_error_responses=1
# 启用 TCP SYN cookies,防 SYN 洪水攻击
net.ipv4.tcp_syncookies=1
net.ipv4.tcp_rfc1337 = 1
# 设置 TCP 半连接超时为 10s,提高连接建立效率
net.netfilter.nf_conntrack_tcp_timeout_syn_recv=10
# Conntrack 建立连接超时为 3600s(1 小时),平衡资源与持久性;高流量路由可缩短至 1800s
net.netfilter.nf_conntrack_tcp_timeout_established=3600
# 缩短 FIN 超时时间,加速连接关闭
net.ipv4.tcp_fin_timeout=15
# 宽松跟踪
net.netfilter.nf_conntrack_tcp_loose=1
# 缩短 TCP CLOSE_WAIT 超时
net.netfilter.nf_conntrack_tcp_timeout_close_wait=60
# 缩短 TCP TIME_WAIT 超时,释放端口更快
net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
# 通用 Conntrack 超时为 300s,适用于非 TCP/UDP 协议;防资源泄漏
net.netfilter.nf_conntrack_generic_timeout=300
# 增大 Conntrack 最大连接数,支持高并发路由
net.netfilter.nf_conntrack_max=1048576
# core dump 优化
kernel.core_uses_pid=1
# TCP Keepalive 时间为 300s(5 分钟),检测死连接
net.ipv4.tcp_keepalive_time=300
# Keepalive 探测间隔 60s
net.ipv4.tcp_keepalive_intvl=15
# Keepalive 最大探测次数 5 次
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_synack_retries=2
# 本地端口范围 1024-65535,支持更多并发连接
net.ipv4.ip_local_port_range=2000 65535
# TCP 接收缓冲区(最小、默认、最大),优化高延迟网络
net.ipv4.tcp_rmem=8192 87380 33554432
# TCP 发送缓冲区(最小、默认、最大),提升发送性能
net.ipv4.tcp_wmem=8192 87380 33554432
# 网络接口接收缓冲区最大值
net.core.rmem_max=67108864
# 网络接口发送缓冲区最大值
net.core.wmem_max=67108864
# UDP 接收缓冲区最小值,优化 UDP 流量(如 DNS、DHCP);防止小包丢弃
net.ipv4.udp_rmem_min = 16384
# UDP 发送缓冲区最小值,提升 UDP 突发性能
net.ipv4.udp_wmem_min = 16384
# TCP 监听队列长度,支持更多并发
net.core.somaxconn=65536
# SYN 后备队列长度,防 SYN 洪水
net.ipv4.tcp_max_syn_backlog=8192
# 网络接口输入队列最大长度,防高负载丢包
net.core.netdev_max_backlog=500000
# TCP 窗口缩放启用,提高长距离网络性能
net.ipv4.tcp_window_scaling=1
# TCP 拥塞控制算法为 BBR,适合高带宽延迟网络
net.ipv4.tcp_congestion_control=bbr
# 启用 TCP Fast Open,减少连接建立 RTT
net.ipv4.tcp_fastopen=3
# 切换到 VyOS 推荐的 fq_codel 队列
net.core.default_qdisc=fq_codel
# IPv6 路由垃圾回收阈值
net.ipv6.route.gc_thresh=1024
# IPv6 接受RA消息,可以通过SLAAC获取到IPv6地址
net.ipv6.conf.all.accept_ra=2
# 文件系统事件通知队列最大数,提高监控性能
fs.fanotify.max_queued_events=65536
# 每个用户最大监控文件/目录数
fs.inotify.max_user_watches=524288
# 系统最大文件描述符数
fs.file-max=2097152
# ARP 缓存垃圾回收阈值,防止 ARP 风暴
net.ipv4.neigh.default.gc_thresh1=4096
net.ipv4.neigh.default.gc_thresh2=8192
net.ipv4.neigh.default.gc_thresh3=16384
# 允许 TIME_WAIT 套接字复用新连接;加速端口回收 15-20%。
net.ipv4.tcp_tw_reuse=1
# 增大 TIME_WAIT 桶限,防端口耗尽;高并发必需
net.ipv4.tcp_max_tw_buckets=1440000
# 启用 MTU 探测,支持 Jumbo Frames;提升大包吞吐 10%
net.ipv4.tcp_mtu_probing=1
# 增大 ancillary 缓冲,支持 UDP/TCP 选项;低开销优化
net.core.optmem_max=25165824
net.ipv4.tcp_mem = 786432 1048576 26777216
# 哈希桶数匹配 conntrack_max/4;加速查找,减少cpu消耗
net.netfilter.nf_conntrack_buckets=262144
# 增大V4路由最大条目数
net.ipv4.route.max_size=1048576
# 增大V6路由最大条目数
net.ipv6.route.max_size=131072
# 设置路由缓存垃圾回收(GC)的超时时间
net.ipv4.route.gc_timeout=100
net.ipv6.route.gc_timeout=100
# ARP缓存条目有效期
net.ipv4.neigh.default.base_reachable_time=30000
# 过期ARP缓存条目的垃圾回收检查时间间隔
net.ipv4.neigh.default.gc_stale_time=75000
# 禁止内核指针暴露,提高安全
kernel.kptr_restrict=2
# 减少调度开销
kernel.sched_autogroup_enabled=0
# 每个 CPU 轮询最大包数(默认 300,提升到 6000 处理高 PPS)
net.core.netdev_budget = 6000
# 轮询周期最大微秒(默认 2000,延长到 8000 减少切换,适合 >1Gbps)
net.core.netdev_budget_usecs=9000
net.core.rmem_default=67108864
net.core.wmem_default=67108864
# NUMA 优化,单CPU用0,多cpu用1或4
vm.zone_reclaim_mode=0
# 禁用swap
vm.swappiness = 0
vm.dirty_ratio = 60
vm.dirty_background_ratio = 2
# RPS/RFS:CPU 包转向(轮询核心)
net.core.rps_sock_flow_entries = 32768
# NAPI 权重(默认 64,提升聚合更多包)
net.core.dev_weight = 128
# 允许TCP套接字接受来自任何VRF的连接
net.ipv4.tcp_l3mdev_accept = 1
# 允许UDP套接字接受来自任何VRF的
net.ipv4.udp_l3mdev_accept = 1
# 允许RAW套接字接受来自任何VRF的连接
net.ipv4.raw_l3mdev_accept = 1
# 启用 Selective ACK(SACK),优化丢包恢复;TCP 性能提升 5-10%
net.ipv4.tcp_sack = 1
# 启用 D-SACK(Dup SACK),报告重复 ACK 以细化拥塞控制
net.ipv4.tcp_dsack = 1
# 启用 Forward ACK(FACK),结合 SACK 改进拥塞窗口计算;适合高丢包链路
net.ipv4.tcp_fack = 1
# 固定2048页 * 2MB = 4096MB内存给数据转发使用,内存足够多时再开启,通常设置为总内存的一半,不会增加耗电。
# 4096的内存够支持 10-40+ Mpps(百万包/秒)或 10-100 Gbps 线速转发。
# 如果是1G和2.5G的速率,设置为1024页(2048MB)内存非常充足
vm.nr_hugepages=1024刷新内核参数
sysctl -p某些系统发行版可能在系统启动时不加载sysctl.conf文件,可以在系统重启后查看所有加载的参数中有没有刚才设置的sysctl -a,没有的话需要将文件重命名为10-user.conf后放入/etc/sysctl.d/目录下
禁用Swap分区
在高 PPS 场景,swap 可能导致 OOM(Out of Memory)崩溃或 thrashing(过度分页),而非优雅降级。Kubernetes 等实时系统也强制禁用 swap 以隔离性能。
sudo swapoff -a
echo 'vm.swappiness = 0' | sudo tee -a /etc/sysctl.conf
sudo sysctl -p21、修改routel,使用C++重写
重写后的程序运行时的CPU消耗仅仅比ip route 命令查看时增加了一点,但是换来的却是美观整洁的界面和丰富的参数效果
在6000条路由显示时,time ip route show table all的real为0m0.023s,而重写后的routel使用time routel -p all的real为0m0.027s
vim routel.cpp// SPDX-License-Identifier: GPL-2.0
//
// Streamed route display - colorized, paginated, ultra-low-CPU display
// Further optimized: Inline batch output with raw write(2), no temp per-row bufs.
#include <iostream>
#include <vector>
#include <string>
#include <unordered_map>
#include <cstdlib>
#include <cstdio>
#include <cstring>
#include <termios.h>
#include <unistd.h>
#include <sys/select.h>
#include <signal.h>
#include <getopt.h>
#include <ctype.h> // for tolower
#include <sstream>
using namespace std;
const string C_RESET = "\033[0m";
const string C_BLUE = "\033[34m";
const string C_YELLOW = "\033[33m";
const string C_MAGENTA = "\033[35m";
const string C_WHITE = "\033[37m";
const string C_RED = "\033[31m";
string g_dashline;
string g_family_str;
size_t g_total;
size_t g_inner_width;
vector<size_t> g_colw;
vector<string> g_color_seq;
char g_pattern_lower[1024]; // For fast case-insensitive search
vector<string> g_all_raw; // Store raw lines
vector<vector<string>> g_display_rows; // Store parsed display rows
// Parse: Use stringstream for efficient split, minimal allocations
vector<string> fast_split(const string& line_str) {
vector<string> parts;
parts.reserve(10); // Estimate tokens per line
stringstream ss(line_str);
string token;
while (ss >> token) {
parts.push_back(std::move(token));
}
return parts;
}
void update_colw(const vector<string>& row, vector<size_t>& colw) {
for (int j = 0; j < 8; ++j) {
size_t len = row[j].length();
if (len > colw[j]) colw[j] = len;
}
}
void sigint_handler(int sig) {
fprintf(stdout, "%s\n", g_dashline.c_str());
fprintf(stdout, "Terminated by user.\n");
exit(0);
}
bool wait_space() {
fprintf(stdout, "......Press <space> for next page, Ctrl+C to quit......");
fflush(stdout);
int fd = STDIN_FILENO;
struct termios oldt, newt;
if (tcgetattr(fd, &oldt) != 0) return false;
newt = oldt;
cfmakeraw(&newt);
tcsetattr(fd, TCSADRAIN, &newt);
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(fd, &rfds);
int ret = select(fd + 1, &rfds, NULL, NULL, NULL);
bool is_space = false;
if (ret > 0 && FD_ISSET(fd, &rfds)) {
char ch;
if (read(fd, &ch, 1) == 1) {
is_space = (ch == ' ');
}
}
fprintf(stdout, "\r%*s\r", 60, " ");
fflush(stdout);
tcsetattr(fd, TCSADRAIN, &oldt);
return is_space;
}
// Fast case-insensitive search using strstr on lowercased pattern
bool fast_match(const char* line, const char* pat_lower) {
if (!pat_lower || !*pat_lower) return true;
char line_lower[2048];
size_t len = strlen(line);
if (len >= sizeof(line_lower)) return false;
for (size_t i = 0; i < len; ++i) {
line_lower[i] = tolower(static_cast<unsigned char>(line[i]));
}
line_lower[len] = '\0';
return strstr(line_lower, pat_lower) != NULL;
}
// Read all raw lines
void read_all_raw(FILE* proc) {
char buf[2048];
while (fgets(buf, sizeof(buf), proc)) {
size_t len = strlen(buf);
if (len > 0 && buf[len-1] == '\n') buf[len-1] = '\0';
if (len > 0) {
g_all_raw.emplace_back(buf);
}
}
}
// Parse single line to row, update colw if needed
vector<string> parse_single_line(const string& line_str, const string& default_table_, const unordered_map<string, string>& special_scopes, bool update_width) {
const auto parts = fast_split(line_str);
if (parts.empty()) return {};
string default_protocol = "kernel";
string default_scope = "global";
string default_metric = "0";
vector<string> row(8, "/");
row[3] = default_protocol;
row[4] = default_scope;
row[5] = default_metric;
row[7] = default_table_;
size_t i = 0;
bool is_special = special_scopes.count(parts[0]);
if (is_special) {
row[0] = (parts.size() > 1 ? parts[1] : "/");
row[3] = "kernel";
row[4] = special_scopes.at(parts[0]);
i = 2;
} else {
row[0] = parts[0];
i = 1;
}
size_t plen = parts.size();
while (i < plen) {
if (i + 1 >= plen) break;
string key = parts[i];
string val = parts[i + 1];
if (key == "via") row[1] = val;
else if (key == "dev") row[6] = val;
else if (key == "proto") row[3] = val;
else if (key == "scope") row[4] = val;
else if (key == "metric") row[5] = val;
else if (key == "src") row[2] = val;
else if (key == "table") row[7] = val;
i += 2;
}
if (update_width) update_colw(row, g_colw);
return row;
}
// NEW: Inline row formatting directly into a pointer (no per-row buf, for batch efficiency)
void append_row_to_buf(const vector<string>& row, char*& buf_ptr, size_t& remaining) {
// "| "
if (remaining >= 2) {
memcpy(buf_ptr, "| ", 2);
buf_ptr += 2;
remaining -= 2;
}
for (int j = 0; j < 8; ++j) {
if (j > 0) {
if (remaining >= 2) {
memcpy(buf_ptr, " ", 2);
buf_ptr += 2;
remaining -= 2;
}
}
const string& field = row[j];
int field_w = static_cast<int>(g_colw[j]);
if (field != "/") {
// Color + field + pad + reset (snprintf for pad calc)
int pad = field_w - static_cast<int>(field.length());
size_t color_len = g_color_seq[j].length();
size_t reset_len = C_RESET.length();
size_t est = color_len + field.length() + pad + reset_len;
if (remaining >= est) {
// Direct memcpy for fixed parts + snprintf only for pad
memcpy(buf_ptr, g_color_seq[j].c_str(), color_len);
buf_ptr += color_len;
remaining -= color_len;
memcpy(buf_ptr, field.c_str(), field.length());
buf_ptr += field.length();
remaining -= field.length();
if (pad > 0 && remaining >= static_cast<size_t>(pad)) {
memset(buf_ptr, ' ', pad); // Faster than snprintf for spaces
buf_ptr += pad;
remaining -= pad;
}
memcpy(buf_ptr, C_RESET.c_str(), reset_len);
buf_ptr += reset_len;
remaining -= reset_len;
}
} else {
if (remaining >= static_cast<size_t>(field_w)) {
memcpy(buf_ptr, field.c_str(), field.length());
buf_ptr += field.length();
remaining -= field.length();
int pad = field_w - static_cast<int>(field.length());
if (pad > 0 && remaining >= static_cast<size_t>(pad)) {
memset(buf_ptr, ' ', pad);
buf_ptr += pad;
remaining -= pad;
}
}
}
}
// " |\n"
if (remaining >= 3) {
memcpy(buf_ptr, " |\n", 3);
buf_ptr += 3;
remaining -= 3;
}
}
// NEW: Batch print: Inline append rows to large buf, then single write(2)
void batch_print_rows(const vector<vector<string>>& rows, size_t start, size_t end, int out_fd) {
char page_buf[65536]; // Larger 64kB for 200+ rows (~300B/row)
char* page_ptr = page_buf;
size_t page_remaining = sizeof(page_buf);
for (size_t j = start; j < end; ++j) {
append_row_to_buf(rows[j], page_ptr, page_remaining);
if (page_remaining < 2048) { // Flush if low (~10 rows left)
size_t written = sizeof(page_buf) - page_remaining;
if (written > 0) {
ssize_t res = write(out_fd, page_buf, written);
(void)res; // FIXED: Capture return value and ignore to fully suppress warning
}
page_ptr = page_buf;
page_remaining = sizeof(page_buf);
}
}
// Final flush
size_t final_written = sizeof(page_buf) - page_remaining;
if (final_written > 0) {
ssize_t res = write(1, page_buf, final_written); // STDOUT_FILENO=1
(void)res; // FIXED: Capture return value and ignore to fully suppress warning
}
}
void print_header(FILE* out) {
static const char* keys[8] = {"Dst", "Gateway", "Prefsrc", "Protocol", "Scope", "Metric", "Dev", "Table"};
char header_buf[2048];
char* hptr = header_buf;
size_t hrem = sizeof(header_buf) - 1;
// FIXED: Match data rows: "| " (add space after |)
if (hrem >= 2) {
memcpy(hptr, "| ", 2);
hptr += 2;
hrem -= 2;
}
size_t blue_len = C_BLUE.length();
if (hrem >= blue_len) {
memcpy(hptr, C_BLUE.c_str(), blue_len);
hptr += blue_len;
hrem -= blue_len;
}
for (int i = 0; i < 8; ++i) {
if (i > 0) {
if (hrem >= 2) {
memcpy(hptr, " ", 2);
hptr += 2;
hrem -= 2;
}
}
int kw = static_cast<int>(g_colw[i]);
size_t klen = strlen(keys[i]);
if (hrem >= klen) {
memcpy(hptr, keys[i], klen);
hptr += klen;
hrem -= klen;
}
int pad = kw - static_cast<int>(klen);
if (pad > 0 && hrem >= static_cast<size_t>(pad)) {
memset(hptr, ' ', pad);
hptr += pad;
hrem -= pad;
}
}
// FIXED: Match data rows: " |\n" (add space before |) + reset color before suffix
size_t reset_len = C_RESET.length();
if (hrem >= reset_len) {
memcpy(hptr, C_RESET.c_str(), reset_len);
hptr += reset_len;
hrem -= reset_len;
}
if (hrem >= 3) {
*hptr++ = ' ';
hrem -= 1;
memcpy(hptr, "|\n", 2);
hptr += 2;
hrem -= 2;
}
*hptr = '\0';
fputs(header_buf, out);
fflush(out);
}
void print_total(FILE* out) {
char total_buf[2048];
char text[256];
snprintf(text, sizeof(text), "%s Routes: %zu", g_family_str.c_str(), g_total);
size_t text_len = strlen(text);
size_t pad_left = (g_inner_width - text_len) / 2;
size_t pad_right = g_inner_width - text_len - pad_left;
char* tptr = total_buf;
size_t trem = sizeof(total_buf) - 1;
if (trem >= 1) *tptr++ = '|';
trem -= 1;
size_t blue_len = C_BLUE.length();
if (trem >= blue_len) {
memcpy(tptr, C_BLUE.c_str(), blue_len);
tptr += blue_len;
trem -= blue_len;
}
if (trem >= pad_left + text_len + pad_right) {
memset(tptr, ' ', pad_left);
tptr += pad_left;
trem -= pad_left;
memcpy(tptr, text, text_len);
tptr += text_len;
trem -= text_len;
memset(tptr, ' ', pad_right);
tptr += pad_right;
trem -= pad_right;
}
size_t reset_len = C_RESET.length();
if (trem >= reset_len) {
memcpy(tptr, C_RESET.c_str(), reset_len);
tptr += reset_len;
trem -= reset_len;
}
if (trem >= 2) {
memcpy(tptr, "|\n", 2);
tptr += 2;
trem -= 2;
}
*tptr = '\0';
fputs(total_buf, out);
fflush(out);
}
int main(int argc, char* argv[]) {
// Buffered output for low CPU syscalls
char buf[BUFSIZ];
setvbuf(stdout, buf, _IOFBF, BUFSIZ);
string family = "inet";
size_t page_size = 200;
bool page_all = false;
bool do_filter = false;
char pattern[1024] = {0};
string table = "all";
int opt;
while ((opt = getopt(argc, argv, "h46f:i:p:t:")) != -1) {
switch (opt) {
case 'h':
fprintf(stdout, "Usage: %s [-4|-6] [-p N|all] [-i PATTERN] [-t TABLE]\n", argv[0]);
return 0;
case '4': family = "inet"; break;
case '6': family = "inet6"; break;
case 'f': family = optarg; break;
case 'p':
if (strcmp(optarg, "all") == 0) page_all = true;
else page_size = atoi(optarg);
break;
case 'i': strncpy(pattern, optarg, sizeof(pattern)-1); do_filter = true; break;
case 't': table = optarg; break;
default: return 1;
}
}
// Lowercase pattern for fast match
if (do_filter) {
strncpy(g_pattern_lower, pattern, sizeof(g_pattern_lower)-1);
g_pattern_lower[sizeof(g_pattern_lower)-1] = '\0';
for (int i = 0; g_pattern_lower[i]; ++i) g_pattern_lower[i] = tolower(static_cast<unsigned char>(g_pattern_lower[i]));
}
g_all_raw.reserve(8192); // Pre-allocate for stability
char cmd_str[1024];
snprintf(cmd_str, sizeof(cmd_str), "ip -f %s route list table %s", family.c_str(), table.c_str());
FILE* proc = popen(cmd_str, "r");
if (!proc) {
perror("popen failed");
return 1;
}
// Read all raw lines first
read_all_raw(proc);
pclose(proc);
if (g_all_raw.empty()) return 0;
g_total = g_all_raw.size();
string default_table_ = (table == "all" ? "main" : table);
// Single pass: compute colw and store display rows
unordered_map<string, string> special_scopes = {
{"local", "host"}, {"anycast", "host"}, {"multicast", "link"}, {"broadcast", "global"}
};
const char* ckeys[8] = {"Dst", "Gateway", "Prefsrc", "Protocol", "Scope", "Metric", "Dev", "Table"};
g_colw.resize(8);
for (int i = 0; i < 8; ++i) g_colw[i] = strlen(ckeys[i]);
g_display_rows.reserve(g_total); // Pre-allocate for stability
if (do_filter) {
vector<string> process_lines;
process_lines.reserve(g_total / 2); // Estimate half match
for (const auto& line : g_all_raw) {
if (fast_match(line.c_str(), g_pattern_lower)) {
process_lines.push_back(line);
}
}
for (const auto& line : process_lines) {
auto row = parse_single_line(line, default_table_, special_scopes, true);
if (!row.empty()) {
g_display_rows.push_back(std::move(row));
}
}
} else {
for (const auto& line : g_all_raw) {
auto row = parse_single_line(line, default_table_, special_scopes, true);
if (!row.empty()) {
g_display_rows.push_back(std::move(row));
}
}
}
size_t num_cols = 8;
size_t visible_len = 0;
for (auto w : g_colw) visible_len += w;
visible_len += 2 * (num_cols - 1); // Match Python calculation
g_inner_width = visible_len + 2;
g_dashline = string(visible_len + 4, '-');
g_family_str = (family == "inet" ? "IPv4" : "IPv6");
g_color_seq = {C_YELLOW, C_MAGENTA, C_WHITE, C_RED, C_WHITE, C_WHITE, C_BLUE, C_WHITE};
fprintf(stdout, "%s\n", g_dashline.c_str());
print_total(stdout);
fprintf(stdout, "%s\n", g_dashline.c_str());
print_header(stdout);
fprintf(stdout, "%s\n", g_dashline.c_str());
fflush(stdout); // Flush header
signal(SIGINT, sigint_handler);
if (g_total == 0) {
fprintf(stdout, "%s\n", g_dashline.c_str());
return 0;
}
size_t display_total = g_display_rows.size();
int out_fd = STDOUT_FILENO; // For write(2)
if (page_all || display_total <= page_size) {
// For small output, use batch (1 big write)
batch_print_rows(g_display_rows, 0, display_total, out_fd);
} else {
size_t i = 0;
while (i < display_total) {
size_t end = i + page_size;
if (end > display_total) end = display_total;
batch_print_rows(g_display_rows, i, end, out_fd);
i = end;
if (i < display_total && !wait_space()) break;
}
}
fprintf(stdout, "%s\n", g_dashline.c_str());
fflush(stdout);
return 0;
}效果如下
root@SoftRouting:~# routel -p 20
----------------------------------------------------------------------------------------------
| IPv4 Routes: 5534 |
----------------------------------------------------------------------------------------------
| Dst Gateway Prefsrc Protocol Scope Metric Dev Table |
----------------------------------------------------------------------------------------------
| 58.215.xxx.xxx 192.168.71.1 192.168.10.254 static global 0 eth0 220 |
| 172.66.4.0/23 192.168.71.1 192.168.10.254 static global 0 eth0 220 |
| 192.168.1.1 192.168.71.1 192.168.10.254 static global 0 eth0 220 |
| 0.0.0.0/1 / / kernel link 0 wg0 main |
| default 192.168.71.1 192.168.71.93 dhcp global 114 eth0 main |
| 1.0.1.0/24 192.168.71.1 / kernel global 0 eth0 main |
| 1.0.2.0/23 192.168.71.1 / kernel global 0 eth0 main |
| 1.0.8.0/21 192.168.71.1 / kernel global 0 eth0 main |
| 1.0.32.0/19 192.168.71.1 / kernel global 0 eth0 main |
| 1.1.0.0/24 192.168.71.1 / kernel global 0 eth0 main |
| 1.1.2.0/23 192.168.71.1 / kernel global 0 eth0 main |
| 1.1.4.0/22 192.168.71.1 / kernel global 0 eth0 main |
| 1.1.9.0/24 192.168.71.1 / kernel global 0 eth0 main |
| 1.1.10.0/23 192.168.71.1 / kernel global 0 eth0 main |
| 1.1.12.0/22 192.168.71.1 / kernel global 0 eth0 main |
| 1.1.16.0/20 192.168.71.1 / kernel global 0 eth0 main |
| 1.1.32.0/19 192.168.71.1 / kernel global 0 eth0 main |
| 1.2.0.0/23 192.168.71.1 / kernel global 0 eth0 main |
| 1.2.2.0/24 192.168.71.1 / kernel global 0 eth0 main |
| 1.2.4.0/22 192.168.71.1 / kernel global 0 eth0 main |
----------------------------------------------------------------------------------------------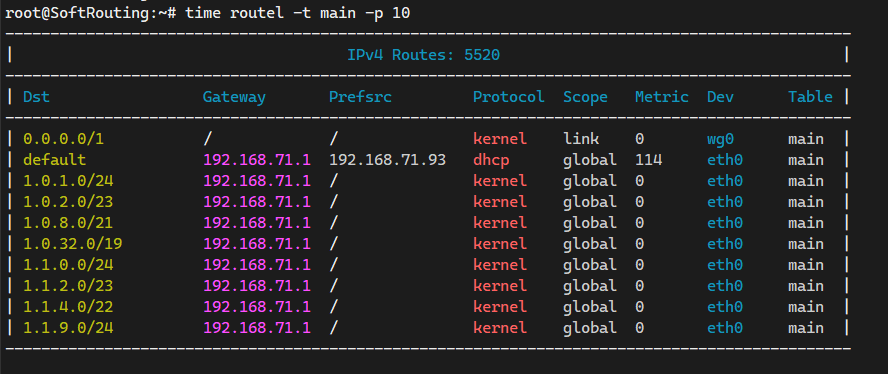
使用方法:
1、routel -i :筛选某条路由
root@SoftRouting:~# routel -i 192.168.10.0/24
----------------------------------------------------------------------------------------------
| IPv4 Routes: 5534 |
----------------------------------------------------------------------------------------------
| Dst Gateway Prefsrc Protocol Scope Metric Dev Table |
----------------------------------------------------------------------------------------------
| 192.168.10.0/24 / 192.168.10.254 kernel link 425 lan main |
----------------------------------------------------------------------------------------------2、routel -p 500:指定打印单页的路由数(默认300条),使用-p all显示当前协议下的所有路由
root@SoftRouting:~# routel -p 500
root@SoftRouting:~# routel -p all3、routel -4/-6:指定查询IPv4/IPv6路由
root@SoftRouting:~# routel -6
-------------------------------------------------------------------------------------------------------------------------------
| IPv6 Routes: 21 |
-------------------------------------------------------------------------------------------------------------------------------
| Dst Gateway Prefsrc Protocol Scope Metric Dev Table |
-------------------------------------------------------------------------------------------------------------------------------
| 240e:b8f:xxxx:xxxx::/64 / / ra global 114 eth0 main |
| ::/1 / / kernel global 1024 wg0 main |
| fd00:10:10:40::/96 / / kernel global 256 wg0 main |
| fe80::/64 / / kernel global 1024 eth0 main |
| fe80::/64 / / kernel global 1024 lan main |
| 8000::/1 / / kernel global 1024 wg0 main |
| default fe80::11ad:7cc9:26ef:5ce / ra global 114 eth0 main |
| ::1 / / kernel host 0 lo local |
| 240e:b8f:xxxx:xxxx:: / / kernel host 0 eth0 local |
| 240e:b8f:xxxx:xxxx:xxxx:xxxx:fe02:1360 / / kernel host 0 eth0 local |
| fd00:10:10:40:: / / kernel host 0 wg0 local |
| fd00:10:10:40::100 / / kernel host 0 wg0 local |
| fe80:: / / kernel host 0 eth0 local |
| fe80:: / / kernel host 0 lan local |
| fe80::499a:3536:69c6:d2bf / / kernel host 0 lan local |
| fe80::62be:b4ff:fe02:1360 / / kernel host 0 eth0 local |
| ff00::/8 / / kernel link 256 eth0 local |
| ff00::/8 / / kernel link 256 wg0 local |
| ff00::/8 / / kernel link 256 eth1 local |
| ff00::/8 / / kernel link 256 wlx0013ef6f25bd local |
| ff00::/8 / / kernel link 256 lan local |
-------------------------------------------------------------------------------------------------------------------------------4、使用“空格”翻页,Ctrl + c结束进程
5、routel -t:指定查询表的名称(默认显示所有表)
root@SoftRouting:~# routel -6 -t local
-------------------------------------------------------------------------------------------------------------
| IPv6 Routes: 14 |
-------------------------------------------------------------------------------------------------------------
| Dst Gateway Prefsrc Protocol Scope Metric Dev Table |
-------------------------------------------------------------------------------------------------------------
| ::1 / / kernel host 0 lo local |
| 240e:b8f:xxxx:xxxx:: / / kernel host 0 eth0 local |
| 240e:b8f:xxxx:xxxx:xxxx:xxxx:fe02:1360 / / kernel host 0 eth0 local |
| fd00:10:10:40:: / / kernel host 0 wg0 local |
| fd00:10:10:40::100 / / kernel host 0 wg0 local |
| fe80:: / / kernel host 0 eth0 local |
| fe80:: / / kernel host 0 lan local |
| fe80::499a:3536:69c6:d2bf / / kernel host 0 lan local |
| fe80::62be:b4ff:fe02:1360 / / kernel host 0 eth0 local |
| ff00::/8 / / kernel link 256 eth0 local |
| ff00::/8 / / kernel link 256 wg0 local |
| ff00::/8 / / kernel link 256 eth1 local |
| ff00::/8 / / kernel link 256 wlx0013ef6f25bd local |
| ff00::/8 / / kernel link 256 lan local |
-------------------------------------------------------------------------------------------------------------22、安装FRR软件
FRR 官方仓库从 frr-7 开始已包含 libyang2 等依赖包,支持 Ubuntu 24.04。这是最简单、稳定的方式,避免版本冲突。
添加 GPG 密钥(验证包签名):
curl -s https://deb.frrouting.org/frr/keys.gpg | sudo tee /usr/share/keyrings/frrouting.gpg > /dev/null添加 FRR 仓库(使用稳定版):
FRRVER="frr-stable" echo "deb [signed-by=/usr/share/keyrings/frrouting.gpg] https://deb.frrouting.org/frr noble $FRRVER" | sudo tee -a /etc/apt/sources.list.d/frr.list更新包列表并安装 FRR:
sudo apt update sudo apt install frr frr-pythontools -y可选插件安装
apt install frr-snmp frr-rpki-rtrlib frr-dbgsym prometheus-frr-exporter
如果aa把frr相关创建文件的权限限制住,导致无法正常使用
mkdir /etc/apparmor.d/disable/
ln -s /usr/lib/frr/* /etc/apparmor.d/disable/随后
apparmor_parser -R /etc/apparmor.d
systemctl restart apparmor
systemctl restart frr23、实时监控包转发速率和带宽
#!/usr/bin/env python3
import time
from collections import defaultdict
import sys
import subprocess
import re
import argparse
def get_net_stats(iface=None):
stats = defaultdict(lambda: [0] * 16) # 16 fields per iface from /proc/net/dev
try:
with open('/proc/net/dev', 'r') as f:
lines = f.readlines()[2:] # Skip header lines
for line in lines:
parts = line.split()
current_iface = parts[0].rstrip(':')
if iface is None or current_iface == iface:
values = [int(x) for x in parts[1:]]
stats[current_iface] = values
if iface is not None and current_iface == iface:
break # Early exit if single iface found
except FileNotFoundError:
# Fallback for non-Linux (rare)
pass
return stats
def get_broadcast_and_multicast_stats(iface):
"""Get rx/tx_broadcast and rx/tx_multicast cumulative values using ethtool -S, fallback for rx_multicast to /proc/net/dev"""
rx_b, tx_b, rx_m, tx_m = 0, 0, 0, 0
try:
result = subprocess.run(['ethtool', '-S', iface], stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, timeout=1)
if result.returncode == 0:
output = result.stdout
rx_b_match = re.search(r'rx_broadcast:\s*(\d+)', output)
tx_b_match = re.search(r'tx_broadcast:\s*(\d+)', output)
rx_m_match = re.search(r'rx_multicast:\s*(\d+)', output)
tx_m_match = re.search(r'tx_multicast:\s*(\d+)', output)
rx_b = int(rx_b_match.group(1)) if rx_b_match else 0
tx_b = int(tx_b_match.group(1)) if tx_b_match else 0
rx_m = int(rx_m_match.group(1)) if rx_m_match else None
tx_m = int(tx_m_match.group(1)) if tx_m_match else 0
if rx_m is not None:
return rx_b, tx_b, rx_m, tx_m
except (subprocess.TimeoutExpired, FileNotFoundError, ValueError, subprocess.SubprocessError):
pass
# Fallback only for rx_multicast to /proc/net/dev (index 7), tx_multicast no fallback
stats = get_net_stats(iface)
if iface in stats:
rx_m = stats[iface][7]
return rx_b, tx_b, rx_m, tx_m
def get_total_width(W):
# Precise width for 8 fields: W + 82
return W + 82
def get_separator(width):
sep_color = "\033[97m"
reset = "\033[0m"
return sep_color + '-' * width + reset
def get_header(W):
header_color = "\033[96;1m"
reset = "\033[0m"
labels = ["rxpck/s", "txpck/s", "rxMbps", "txMbps", "rxbcast/s", "txbcast/s", "rxmcast/s", "txmcast/s"]
fws = [7, 7, 7, 7, 9, 9, 9, 9]
h = header_color
h += "|"
h += "Interface".ljust(W)
h += "| "
for i, label in enumerate(labels):
h += label.rjust(fws[i])
if i < 7:
h += "| "
else:
h += "|"
h += reset
return h
def get_row(iface, rates, W):
rxpck, txpck, rxmbps, txmbps, rxbcast, txbcast, rxmcast, txmcast = rates
rx_active = rxpck > 0 or rxmbps > 0 or rxbcast > 0 or rxmcast > 0
tx_active = txpck > 0 or txmbps > 0 or txbcast > 0 or txmcast > 0
rx_attr = "\033[92;1m" if rx_active else "\033[92m"
tx_attr = "\033[93;1m" if tx_active else "\033[93m"
white = "\033[97m"
reset = "\033[0m"
line = white + "|" + reset
line += white + iface.ljust(W) + reset
line += white + "| " + reset
# Fixed formats: packets as .0f (integer), Mbps as .2f
formats = [">7.0f", ">7.0f", ">7.2f", ">7.2f", ">9.0f", ">9.0f", ">9.0f", ">9.0f"]
rate_attrs = [rx_attr, tx_attr, rx_attr, tx_attr, rx_attr, tx_attr, rx_attr, tx_attr]
for i, (attr, rate) in enumerate(zip(rate_attrs, rates)):
fmt = formats[i]
line += attr + ("{:" + fmt + "}").format(rate) + reset
if i < 7:
line += white + "| " + reset
else:
line += white + "|" + reset
return line
def main():
parser = argparse.ArgumentParser(description='Network interface monitor')
parser.add_argument('-i', '--interface', help='Specify network interface to monitor (default: all except lo)')
args = parser.parse_args()
# Initial stats to check existence and compute max W
initial_stats = get_net_stats(args.interface) if args.interface else get_net_stats()
if args.interface:
if args.interface not in initial_stats:
print(f"Interface not found: {args.interface}", file=sys.stderr)
sys.exit(1)
initial_ifaces = [args.interface]
W = max(12, len(args.interface))
else:
initial_ifaces = sorted(set(initial_stats.keys()) - {'lo'})
W = max(12, max((len(iface) for iface in initial_ifaces), default=0)) if initial_ifaces else 12
# Hide cursor
sys.stdout.write("\033[?25l")
sys.stdout.flush()
total_width = get_total_width(W)
top_sep = get_separator(total_width)
header_line = get_header(W)
mid_sep = get_separator(total_width)
bottom_sep = get_separator(total_width)
# Print fixed header part
initial_lines = [top_sep, header_line, mid_sep, bottom_sep]
sys.stdout.write('\n'.join(initial_lines) + '\n')
sys.stdout.flush()
prev_stats = initial_stats.copy()
# Initialize prev_bcast_mcast with actual cumulative values to avoid initial spike
prev_bcast_mcast = {iface: get_broadcast_and_multicast_stats(iface) for iface in initial_ifaces}
start_time = time.time()
prev_num_lines = len(initial_lines) + 1 # Account for the trailing newline
try:
while True:
current_stats = get_net_stats(args.interface) if args.interface else get_net_stats()
if args.interface:
current_ifaces = [args.interface] if args.interface in current_stats else []
new_W = max(12, len(args.interface)) if current_ifaces else 12
else:
current_ifaces = sorted(set(current_stats.keys()) - {'lo'})
new_W = max(12, max((len(iface) for iface in current_ifaces), default=0)) if current_ifaces else 12
# Update W if new longer iface
if new_W > W:
W = new_W
total_width = get_total_width(W)
top_sep = get_separator(total_width)
header_line = get_header(W)
mid_sep = get_separator(total_width)
bottom_sep = get_separator(total_width)
interval = time.time() - start_time
if interval < 1.0:
time.sleep(0.1)
continue
row_lines = []
for iface in current_ifaces:
prev = prev_stats.get(iface, [0] * 16)
curr = current_stats[iface]
deltas = [curr[i] - prev[i] for i in range(16)]
# Fixed rates_list: round for packet rates, handle d >= 0 and interval > 0
rates_list = [round(max(0, d) / interval) if interval > 0 else 0 for d in deltas]
# Indices: rx_bytes=0, rx_pck=1, tx_bytes=8, tx_pck=9
rxpck = rates_list[1]
txpck = rates_list[9]
# Mbps: keep float for precision (bytes/s * 8 / 1e6)
rx_bytes_rate = max(0, deltas[0]) / interval if interval > 0 else 0
tx_bytes_rate = max(0, deltas[8]) / interval if interval > 0 else 0
rxmbps = rx_bytes_rate * 8 / 1000000
txmbps = tx_bytes_rate * 8 / 1000000
# Broadcast and Multicast: delta from ethtool (with fallback for rxmcast)
curr_bcast_mcast = get_broadcast_and_multicast_stats(iface)
prev_bm = prev_bcast_mcast.get(iface, (0, 0, 0, 0))
# Ensure non-negative delta (in case of counter wrap, though rare)
delta_rx_b = max(0, curr_bcast_mcast[0] - prev_bm[0])
delta_tx_b = max(0, curr_bcast_mcast[1] - prev_bm[1])
delta_rx_m = max(0, curr_bcast_mcast[2] - prev_bm[2])
delta_tx_m = max(0, curr_bcast_mcast[3] - prev_bm[3])
rxbcast = round(delta_rx_b / interval) if interval > 0 else 0
txbcast = round(delta_tx_b / interval) if interval > 0 else 0
rxmcast = round(delta_rx_m / interval) if interval > 0 else 0
txmcast = round(delta_tx_m / interval) if interval > 0 else 0
rates = (rxpck, txpck, rxmbps, txmbps, rxbcast, txbcast, rxmcast, txmcast)
row_lines.append(get_row(iface, rates, W))
prev_bcast_mcast[iface] = curr_bcast_mcast # Update prev
full_lines = [top_sep, header_line, mid_sep] + row_lines + [bottom_sep]
num_lines = len(full_lines) + 1 # Account for the trailing newline
# Move up previous lines and clear down
move_up_clear = "\033[{}A\033[J".format(prev_num_lines - 1) if prev_num_lines > 0 else "" # Adjust for cursor position after trailing newline
output = '\n'.join(full_lines) + '\n'
sys.stdout.write(move_up_clear + output)
sys.stdout.flush()
prev_num_lines = num_lines
start_time = time.time()
prev_stats = current_stats.copy()
except KeyboardInterrupt:
pass
finally:
# Show cursor and move to new line
sys.stdout.write("\033[?25h\n")
sys.stdout.flush()
if __name__ == "__main__":
main()以上脚本写入/usr/bin/packets_show,然后使用chmod + x赋予可执行权限,使用packs_show命令运行,效果如下
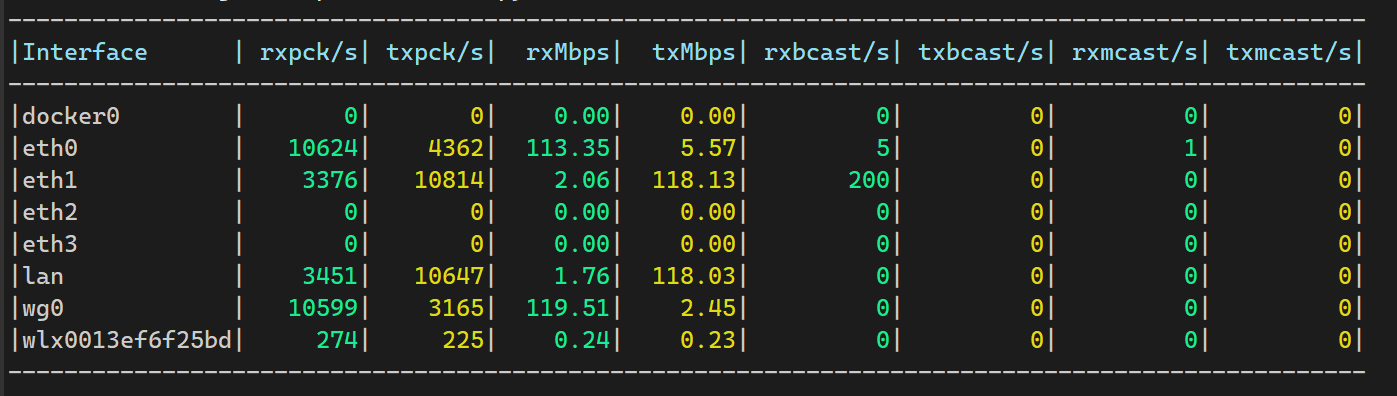
IFACE:接口名称(如 lo、eth0、lan)。
rxpck/s:每秒接收包数(Receive Packets per second)。
txpck/s:每秒发送包数(Transmit Packets per second)。
rxMbps:每秒接收带宽。
txMbps:每秒发送带宽。
rxbcast/s:每秒接收广播包数。
txbcast/s:每秒发送广播包数。
rxmcst/s:每秒接收组播包数(Receive Multicast packets per second,不包括广播)。
txmcst/s:每秒发送组播包数(Receive Multicast packets per second,不包括广播)。
使用-i指定要监控的网卡
root@SoftRouting:~# packs_show -i eth1
----------------------------------------------------------------------------------------------
|Interface | rxpck/s| txpck/s| rxMbps| txMbps| rxbcast/s| txbcast/s| rxmcast/s| txmcast/s|
----------------------------------------------------------------------------------------------
|eth1 | 14| 20| 0.01| 0.02| 0| 0| 0| 0|
----------------------------------------------------------------------------------------------24、XDP快速转发数据
1、安装
apt install xdp-tools -y2、查看自己网卡的支持状况
root@SoftRouting:~# xdp-loader features eth0
NETDEV_XDP_ACT_BASIC: yes
NETDEV_XDP_ACT_REDIRECT: yes
NETDEV_XDP_ACT_NDO_XMIT: no
NETDEV_XDP_ACT_XSK_ZEROCOPY: yes
NETDEV_XDP_ACT_HW_OFFLOAD: no
NETDEV_XDP_ACT_RX_SG: no
NETDEV_XDP_ACT_NDO_XMIT_SG: no可以看到我的设备是支持native模式的XDP的,这可以大大转发数据时的CPU使用率
3、将所有接口加入到xdp-forward中(无需NAT,如核心三层交换机,数据中心等)
xdp-forward load eth0 eth1 eth2 eth3加入到xdp-forward后,默认网卡为native模式(不支持会自动后退),转发模式为:FULL(基于路由表转发,但不是FIB表,不考虑同子网情况)
数据在转发时,经过网卡,XDP程序对数据首包查找路由表,发现跨子网通信且路由表内可找到转发路由且是要跨接口,则直接跨过内核将数据发送到下一个网卡驱动中转发出去,并且将查找路由记录暂存,等到记录过期后才会再次查看路由表。
注意:
1、一定要多端口一起加入,否则xdp-forward转发不会生效;
2、同时加入的网卡相当于一个快速转发组;
4、验证接口状态
root@SoftRouting:~# xdp-loader status
CURRENT XDP PROGRAM STATUS:
Interface Prio Program name Mode ID Tag Chain actions
--------------------------------------------------------------------------------------
lo <No XDP program loaded!>
eth0 xdp_dispatcher native 2835 cec73f7ad6da90d3
=> 50 xdp_fwd_fib_full 2844 034fa5d5054f8caf XDP_PASS
eth1 xdp_dispatcher native 2837 cec73f7a33da90d3
=> 50 xdp_fwd_fib_full 2844 034fa5d5333f8caf XDP_PASS
eth2 xdp_dispatcher native 2837 cec73f7a33da90d3
=> 50 xdp_fwd_fib_full 2844 034fa5d5333f8caf XDP_PASS
eth3 xdp_dispatcher native 2837 cec73f7a33da90d3
=> 50 xdp_fwd_fib_full 2844 034fa5d5333f8caf XDP_PASS5、桥接lan网卡
直接加载到物理网卡 eth1 和 eth2 上(用 native 模式),然后再把 eth1 和 eth2 加入到 lan bridge(比如 br-lan),整个流程是这样的:
首包
客户端A(接 eth1) → 发出 ARP Request(谁是 192.168.10.55?)
↓
eth1 物理口收到 → XDP 程序看到是广播包 → 直接 XDP_PASS(xdp_fwd_fib_full 不处理广播)
↓
进入内核网络栈 → bridge 正常处理广播 → 洪泛(flood)到 eth2、eth3
↓
客户端B(接 eth2)回复 ARP Reply(我是 192.168.10.55,我的 MAC 是 xx:xx:xx:xx:xx:xx)
↓
eth2 物理口收到 → 同样是广播,XDP_PASS → 交给 bridge
↓
bridge 同时做了两件事:
1. 学习:eth2 端口看到客户端B的 MAC → 写入 FDB(MAC → eth2)
2. 转发:把 ARP Reply 发给 eth1
↓
客户端A 收到 Reply,建立好 ARP 表后续包
客户端A → 直接发单播数据包,目的 MAC = 客户端B 的 MAC
↓
eth1 物理口收到 → XDP 程序查 IPv4 FIB,发现目的 IP 192.168.10.55 是本子网
↓
但 xdp_fwd_fib_full 只会根据 IP 路由表决定是否 REDIRECT
→ 路由表显示“直接投递”(dev lan scope link),它认为不需要跨接口
→ 所以仍然返回 XDP_PASS(不是 REDIRECT!)
↓
交给 bridge → bridge 查 FDB,发现目的 MAC 对应 eth2 端口 → 直接从 eth2 发出去在同一个 bridge 下的统一子网里,XDP_REDIRECT 几乎永远不会触发。 真正实现“硬件交换机级高速转发”的其实是 Linux bridge 本身的 FDB 查找 + XDP native 驱动层提速,而不是 xdp_fwd_fib_full 的 REDIRECT
为什么XDP Native可以加速同子网转发?
1、无XDP加载时:网络包从网卡RX队列进入内核时,需要立即分配skb(struct sk_buff,Linux网络包数据结构),然后经过netif_receive_skb()函数进入网络栈。这涉及多次内存分配、CPU中断处理和上下文切换,尤其在高PPS(包/秒)场景下,开销大,导致CPU利用率高、延迟增加。
2、加载XDP(native模式)后,即使返回XDP_PASS:
XDP程序在驱动层(RX队列)最早点执行(在skb分配之前)。程序可以快速检查包(e.g., 头部解析),然后返回PASS。
PASS后,包才分配skb进入内核栈(包括netfilter prerouting/forward等)。
关键优化:XDP在native模式下,netfilter在PASS后正常生效,但XDP预过滤让netfilter只处理有效包,间接优化其性能(减少无效流量进入链)。
结果:加载XDP后,同子网互访的转发延迟降低10-30%,PPS提升(可达线速级别),CPU消耗减少,尤其在高负载下(如内网文件共享、视频流)
无XDP:RX → skb分配 → prerouting → bridge soft-forward(CPU高) → TX;
6、有需要访问互联网的网卡(需要nat,家庭/企业出口)
xdp-forward默认不支持nat,但家庭场景下可能需要可以nat的网卡,这种场景下我们在添加xdp-forward到网卡时不写外网接口即可。
这样的话实现的就是局域网内的高速通信了,属于过渡实现
外网 (wan) ── eth0 (万兆,支持 native XDP) ← 只负责上网,不加载任何 XDP
▲
│ (内核路由 + nf_tables NAT (masquerade)
│
lan bridge (br-lan) ── eth1 ┐
── eth2 ├─ 三个都支持 native XDP
── eth3 ┘支持native的网卡和不支持native的网卡能否一起加入xdp-forward中?不行!可以添加成功,但是高速转发失效
7、检验是否正常快速转发
root@SoftRouting:~# xdp-monitor -s -i 1
Summary 87 redir/s 0 err,drop/s 0 xmit/s
Summary 74 redir/s 0 err,drop/s 0 xmit/s
Summary 66 redir/s 0 err,drop/s 0 xmit/s
Summary 66 redir/s 0 err,drop/s 0 xmit/s
Summary 66 redir/s 0 err,drop/s 0 xmit/s
Summary 66 redir/s 0 err,drop/s 0 xmit/s存在正常被XDP重定向流量的话redir/s会有数值显示
8、systemd开机自动加载
vim /etc/systemd/system/xdp-forward.service[Unit]
Description=Load XDP Forward on Network Interfaces
After=NetworkManager-wait-online.service
Wants=NetworkManager-wait-online.service
[Service]
Type=oneshot
ExecStart=/usr/sbin/xdp-forward load eth1 eth2 eth3
RemainAfterExit=true
ExecStop=/usr/sbin/xdp-forward unload eth1 eth2 eth3
[Install]
WantedBy=multi-user.targetsystemctl start xdp-forward.service
systemctl enable xdp-forward.service